推理 LLM 的可视化指南:探索推理时计算技术与 DeepSeek-R1
推理 LLM 的可视化指南:探索推理时计算技术与 DeepSeek-R1
原文地址:A Visual Guide to Reasoning LLMs
📅 作者:Maarten Grootendorst
📆 日期:2025 年 2 月 3 日
📌 引言
DeepSeek-R1、OpenAI o3-mini 和 Google Gemini 2.0 Flash Thinking 是如何通过“推理”框架将 LLM(大型语言模型, Large Language Models) 扩展到新高度的典型示例。
它们标志着从 扩展训练时计算(train-time compute) 到 扩展推理时计算(test-time compute) 的范式转变。
在本篇文章中,我们提供了 超过 40 张定制可视化图表,带你深入探索:
- 推理 LLM(Reasoning LLMs) 领域
- 推理时计算(Test-Time Compute) 机制
- DeepSeek-R1 的核心思想
我们将逐步介绍相关概念,帮助你建立对这一新范式的直觉理解。
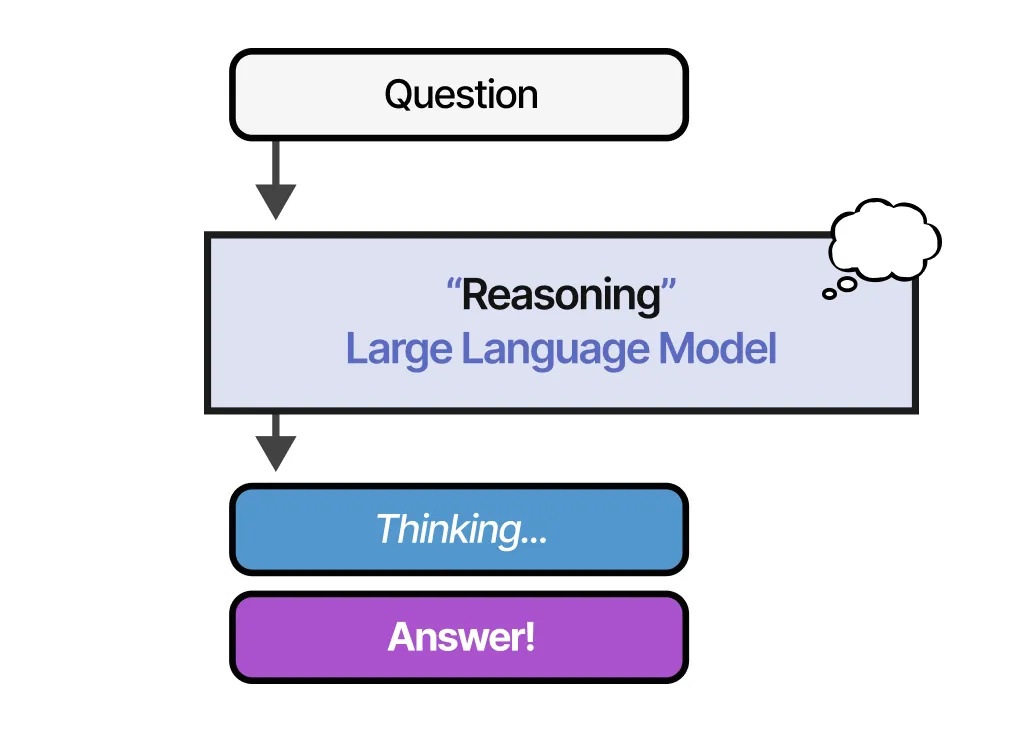
📖 什么是推理 LLM?
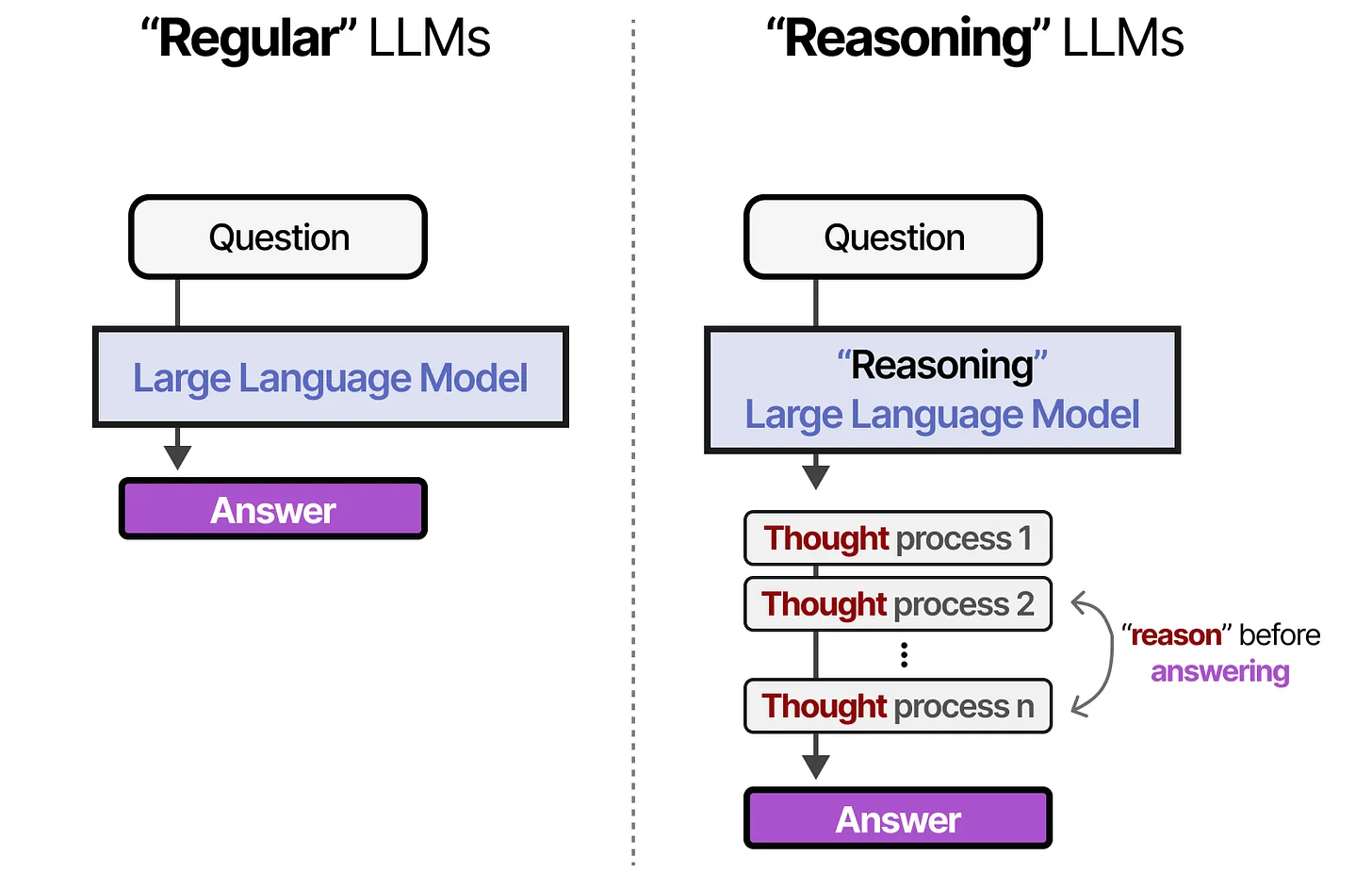
与普通 LLM(Large Language Models,大型语言模型) 相比,推理 LLM 在回答问题之前,往往会将问题 分解为更小的步骤(通常称为 推理步骤(Reasoning Steps) 或 思考过程(Thought Process))。
🧠 “推理步骤” 或 “思考过程” 是什么?
尽管我们可以哲学化地探讨 LLM 是否真的能够像人类一样思考,但这些推理步骤实际上是将推理过程 分解为更小、更结构化的推断。推理 LLM 采用的是结构化推理方式,即:
- 普通 LLM:直接输出答案
- 推理 LLM:通过系统性推理生成答案
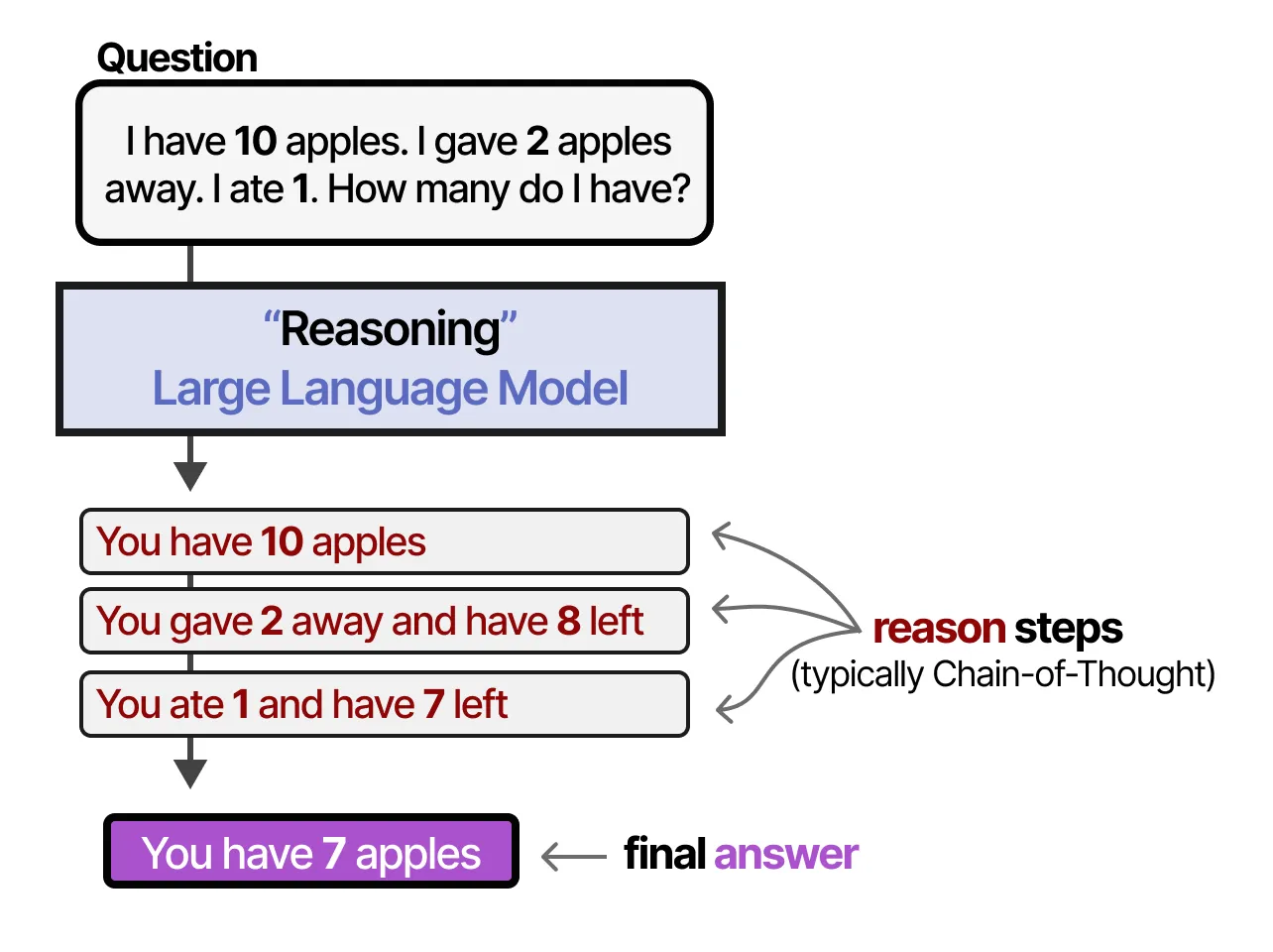
换句话说,推理 LLM 不是学习“回答什么”,而是学习“如何回答”!
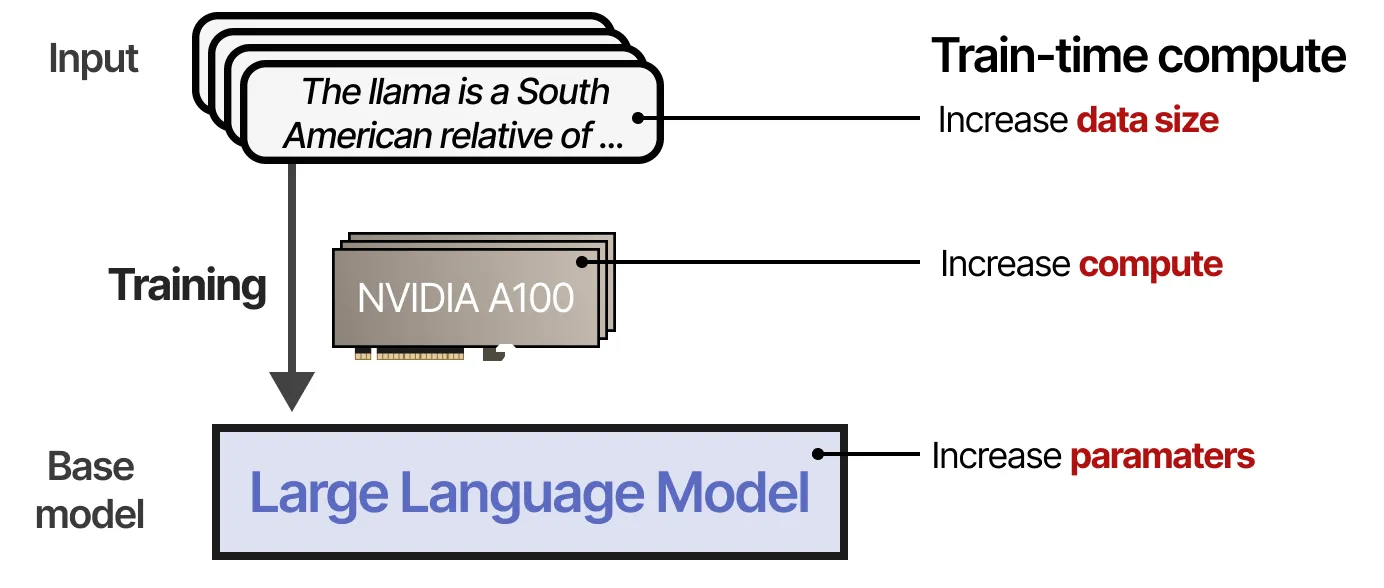
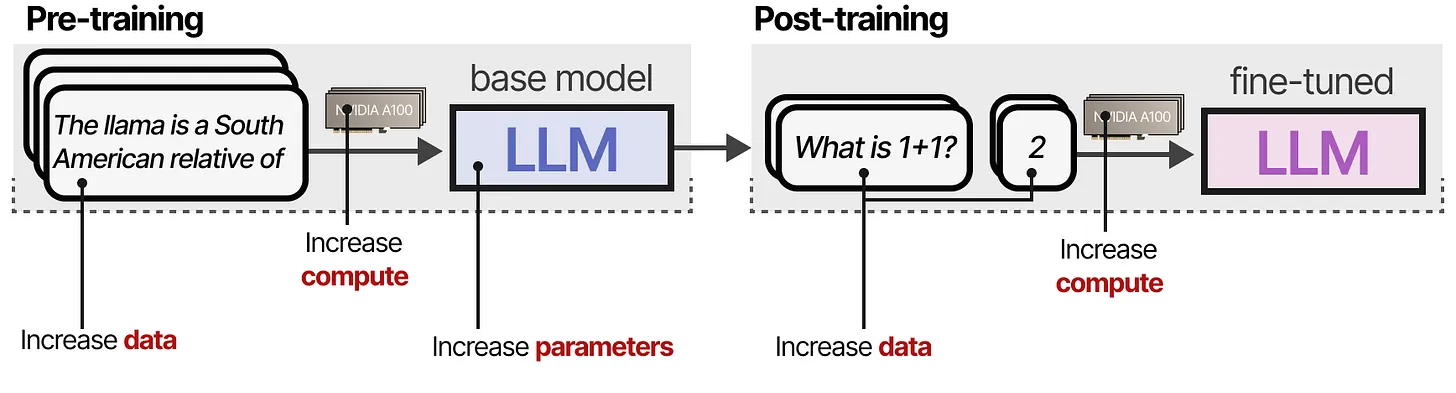
要理解推理 LLM 的构建原理,我们首先需要探讨 训练时计算(Train-Time Compute) 和 推理时计算(Test-Time Compute) 之间的差异。
🔍 什么是训练时计算(Train-time Compute)?
直到 2024 年年中,为了在 预训练(Pretraining) 期间提高 LLM 的性能,研究人员通常会扩大以下规模:
- 模型参数数量(# of Parameters)
- 数据集规模(# of Tokens)
- 计算量(# of FLOPs, Floating Point Operations)
这些合称为 训练时计算(Train-time Compute),即 “AI 的化石燃料”,指的是:
预训练预算越大,最终得到的模型就越好。
训练时计算(Train-Time Compute)包括训练(training)所需的计算,以及微调(fine-tuning)所需的计算。长期以来,一直是提高 LLM 性能的主要关注点。
🔢 规模定律(Scaling Laws)
在 LLM(大型语言模型) 研究领域,模型规模(Scale) 与 模型性能(Performance) 之间的关系被称为 规模定律(Scaling Laws)。这些定律通常用于描述 计算资源、数据规模和模型参数 如何影响模型的整体表现。
这些关系通常以 对数-对数(log-log) 方式呈现,并且在图表上通常显示为一条 近似直线,以突出计算量的巨大增长。
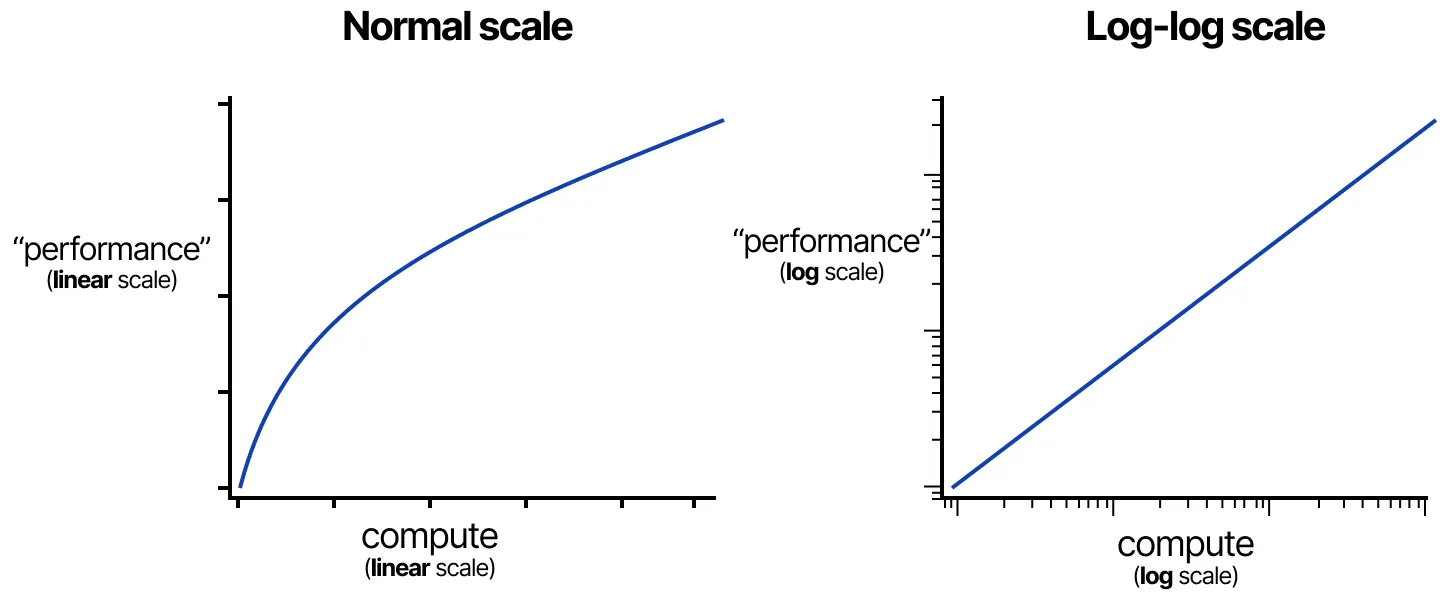
这张图片展示了不同坐标尺度(线性 vs. 对数)对计算资源(Compute)和模型性能(Performance)之间关系的影响,强调了大模型增长的幂律关系(Power Law)。
左图(普通线性尺度 - Normal Scale)
- 横轴(X 轴):计算资源(Compute),线性刻度。
- 纵轴(Y 轴):性能(Performance),线性刻度。
- 曲线显示递减收益(Diminishing Returns),即:随着计算资源的增加,性能增长趋缓,但仍然在上升。
右图(对数-对数尺度 - Log-log Scale)
- 横轴(X 轴):计算资源(Compute),对数刻度。
- 纵轴(Y 轴):性能(Performance),对数刻度。
- 在对数-对数尺度下,原本弯曲的曲线变成一条直线,说明计算资源和性能之间呈幂律关系(Power Law Relationship)。
这些定律通常遵循 幂律(Power Laws),即:
某个变量(如计算量)增加,会导致另一个变量(如性能)按一定比例变化。
最著名的 规模定律 包括:
- Kaplan 规模定律(Kaplan Scaling Law):当计算资源一定时,增加模型的参数规模比增加数据规模更有效。表明模型性能与参数量、计算量和训练数据(Tokens)之间存在幂律关系,即 更多参数、更多计算资源能提升性能(GPT-3 论文提出)。
- Chinchilla 规模定律(Chinchilla Scaling Law):模型的大小和数据规模同样重要,二者需 同步扩展 才能实现最佳性能(DeepMind 提出)。
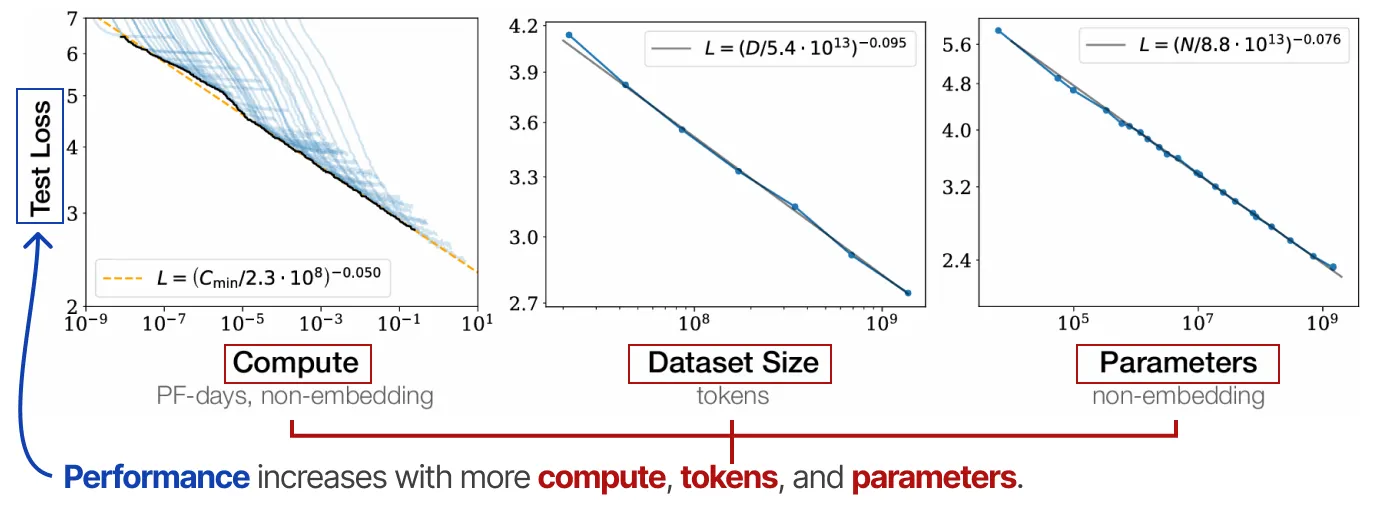
这张图展示了大规模 AI 训练中的 Scaling Laws(缩放定律),表明计算资源(Compute)、数据集规模(Dataset Size)和参数量(Parameters)对模型性能的影响。关键信息如下:
1. 纵轴(Y轴):测试损失(Test Loss)
- 目标是降低测试损失(Test Loss),即提高模型的泛化性能。
- 损失(L)越小,模型性能越好。
2. 横轴(X轴):三种关键变量
左图(Compute,计算资源):
- X 轴是计算资源(PF-days, 非 embedding)。
- 计算资源越多,测试损失降低(性能提升)。
- 公式:
$$
L = \left( \frac{C_{\text{min}}}{2.3 \times 10^8} \right)^{-0.050}
$$ - 体现计算资源的幂律关系:计算资源增加,损失减少,但收益递减(指数 -0.050)。
中图(Dataset Size,数据集规模):
- X 轴是训练数据的 Token 数量。
- 数据规模越大,测试损失降低(性能提升)。
- 公式:
$$
L = \left( \frac{D}{5.4 \times 10^{13}} \right)^{-0.095}
$$ - 数据规模对损失的影响较大(指数 -0.095)。
右图(Parameters,参数量):
- X 轴是模型参数量(非 embedding)。
- 参数数量越大,测试损失降低(性能提升)。
- 公式:
$$
L = \left( \frac{N}{8.8 \times 10^{13}} \right)^{-0.076}
$$ - 参数对损失的影响介于计算资源和数据规模之间(指数 -0.076)。
这些研究表明,模型规模、数据规模和计算资源必须协同扩展,才能最大化模型的性能。
- 计算资源增加 → 训练更强大模型
- 更多 Tokens → 更好泛化能力
- 参数增加 → 但需要与数据匹配,否则过拟合
Kaplan 规模定律认为,在 固定计算资源 的情况下,优先增加模型参数 通常比增加数据规模更有效。而 Chinchilla 规模定律则指出,模型参数和数据规模都应同步增长,以获得更优的模型性能。
然而,在 2024 年,研究人员发现,尽管计算资源、数据规模和模型参数 持续增长,但性能提升的 边际收益(Marginal Return) 却在 逐渐降低。
这引发了一个重要的问题:
❓ “我们是否已经遇到了 LLM 发展的瓶颈?”
🚀 什么是推理时计算(Test-time Compute)?
由于 训练时计算的成本极其昂贵,研究人员开始关注 推理时计算(Test-time Compute),即:
让 LLM 在推理时“思考更长时间”,而非单纯依赖更大的模型和数据集。
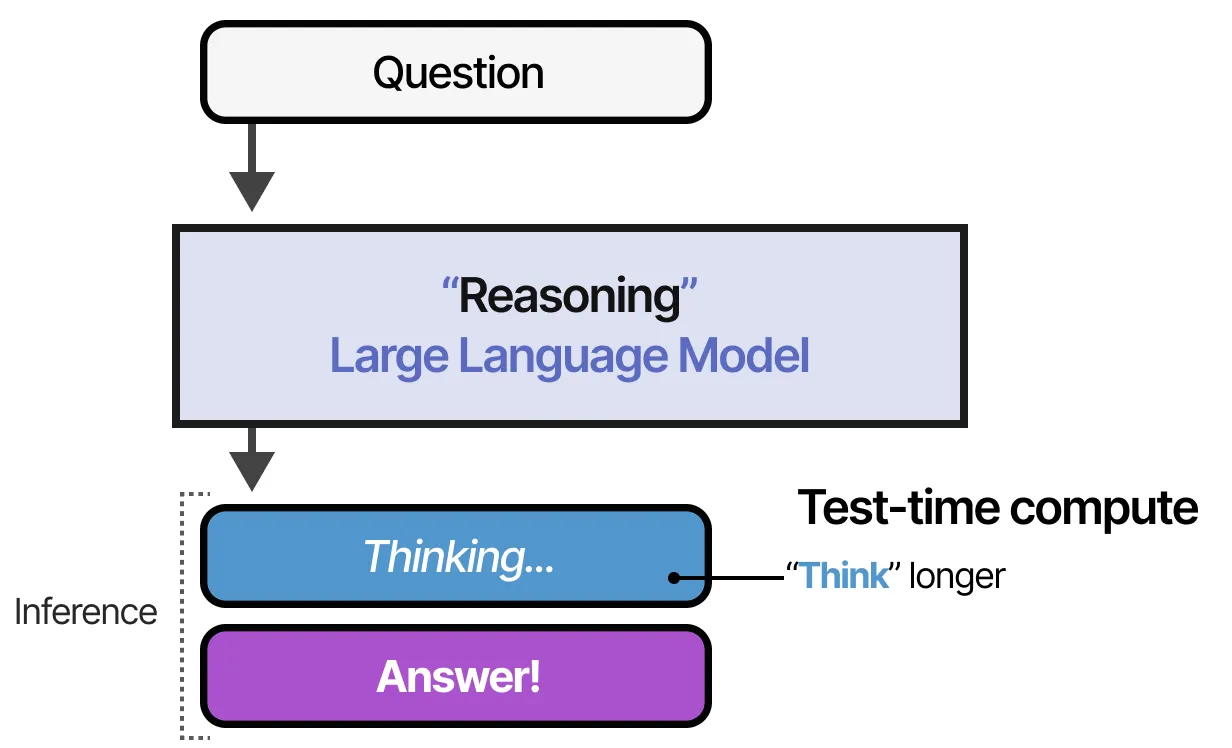
对于非推理模型,它们通常 直接输出答案:
1 | Q: 8 + 5 = ? |
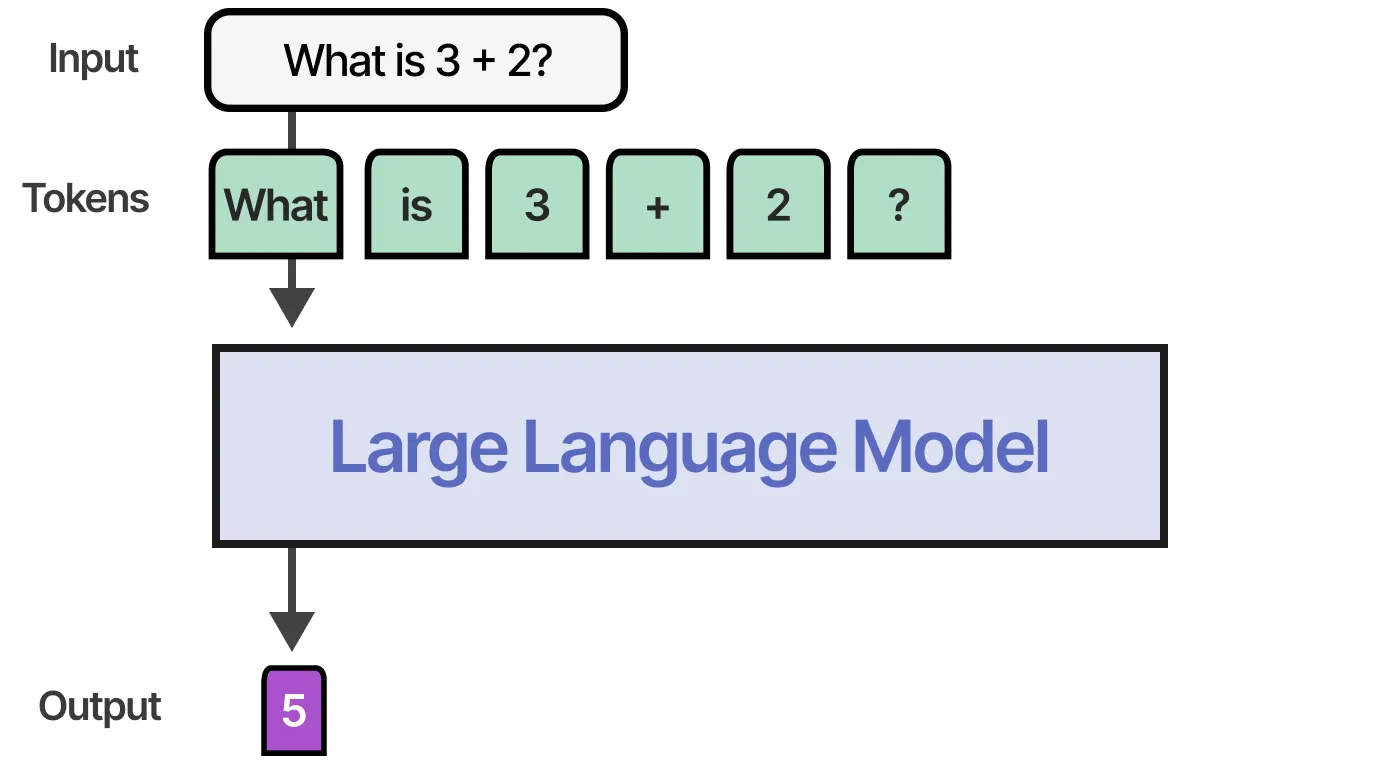
而推理模型则会 使用更多 token 进行推理,形成系统化的“思考”过程:
1 | Q: 8 + 5 = ? |
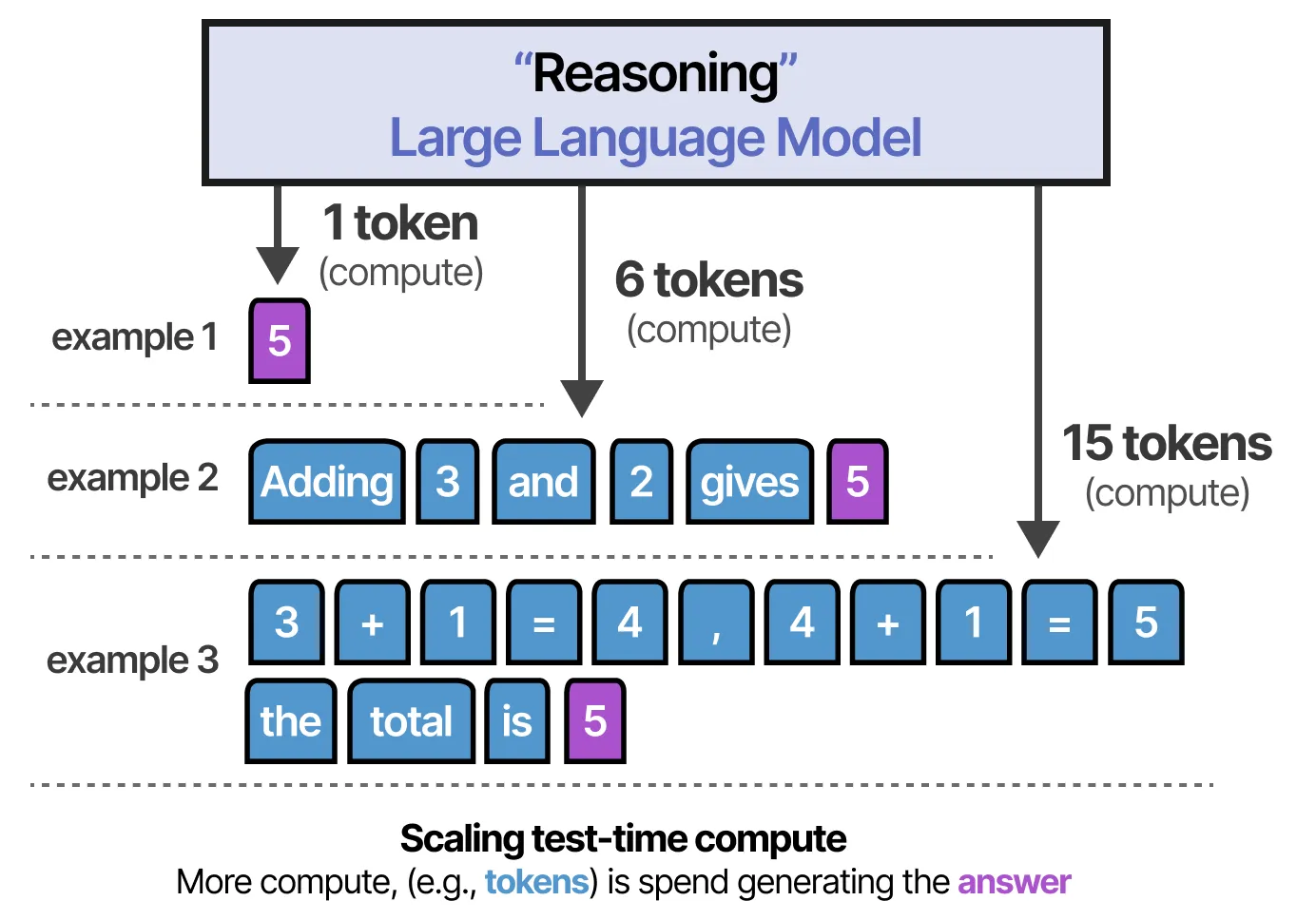
LLM 需要消耗计算资源(如显存计算)来生成答案。然而,如果所有计算资源都用于直接生成答案,那将会是低效的!
相反,通过提前生成包含额外信息、关系和新思考的更多 token,模型可以在推理过程中分配更多计算资源以生成最终答案。
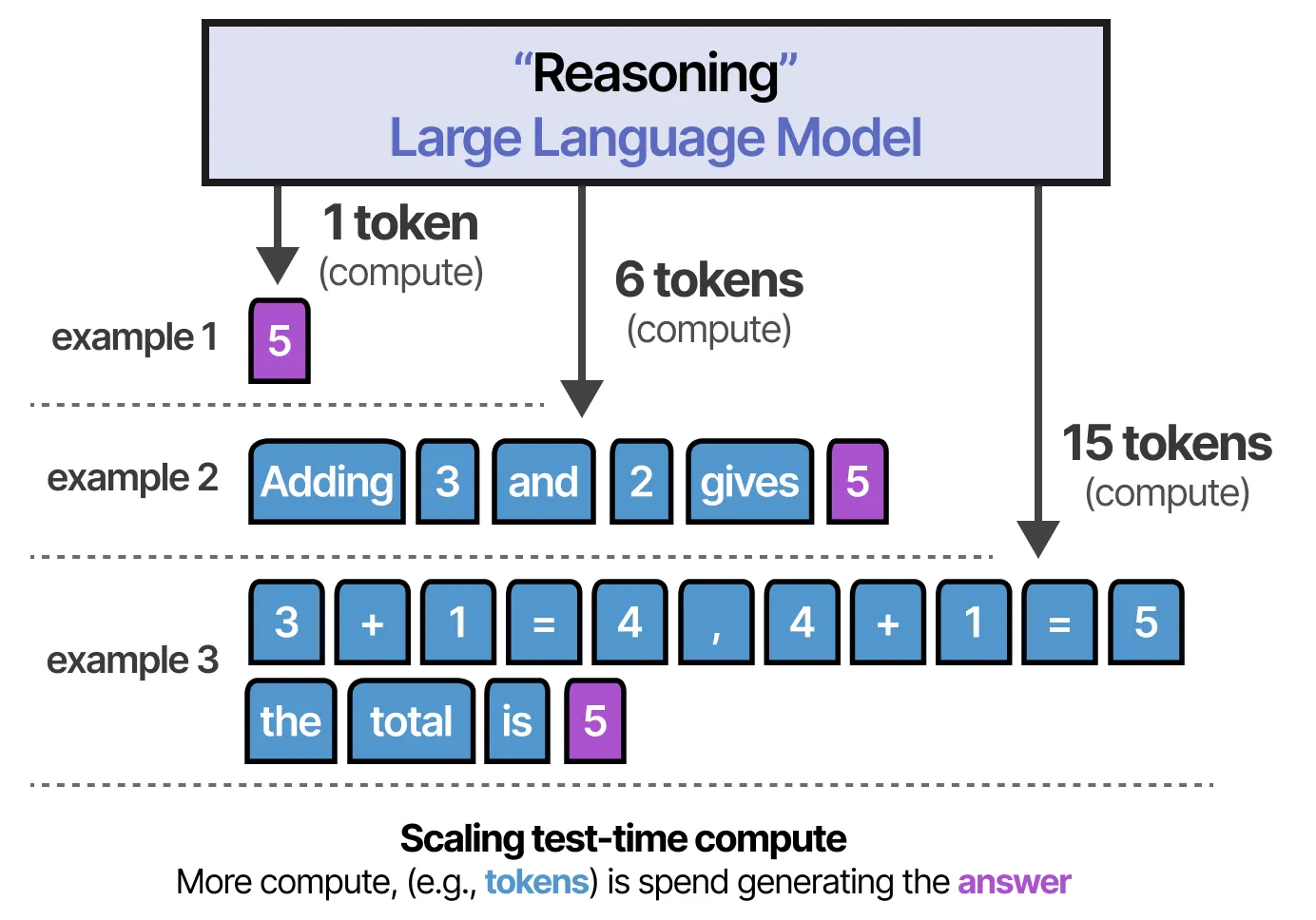
这张图片展示了 大语言模型(LLM) 在计算过程中如何分配 token(标记)来优化推理能力和最终的回答质量。核心思想是:如果计算资源(如 GPU/VRAM 计算量)全部用于直接生成答案,而没有用于思考,那么效率会受到影响。相反,增加 思考过程(即生成更多的中间 token),可以提高模型的 推理能力,从而提升 最终的回答质量。
1. Token 的使用与计算量
- LLM 生成答案是按 token 逐步输出的,每个 token 都会占用计算资源。
- 分配更多的 token 进行思考,意味着模型可以在得出最终答案之前有更多的推理步骤,从而提高正确率。
2. 三种不同的计算方式
场景 1(1 个 token:最少计算)
- 直接输出 “5” 作为答案。
- 计算量最少,速度最快。
- 如果问题较复杂,可能会出错,因为模型没有足够的计算时间来思考。
场景 2(6 个 token:中等计算)
- 模型生成一个简短的推理过程:
1
Adding 3 and 2 gives 5
- 比第一种方法多了一些计算量,但仍然较为简洁。
- 这种方式适用于简单的数学运算或逻辑推理,但在更复杂的情况下仍可能出现错误。
- 模型生成一个简短的推理过程:
场景 3(15 个 token:完整推理)
- 模型先进行详细的逐步推理:然后,模型再明确地总结:
1
3 + 1 = 4 , 4 + 1 = 5
1
the total is 5
- 推理过程更详细,占用的计算量最大。
- 适用于需要多步推理的任务,如数学题、逻辑推理题等。
- 模型先进行详细的逐步推理:
🔢 规模定律(Scaling Laws)
相比于训练时计算,推理时计算的规模定律仍然较为新颖。值得注意的是,有两项研究揭示了推理时计算规模与训练时计算规模的关系。
首先,OpenAI 发表的一篇文章表明,推理时计算可能遵循与训练时计算相同的扩展趋势。
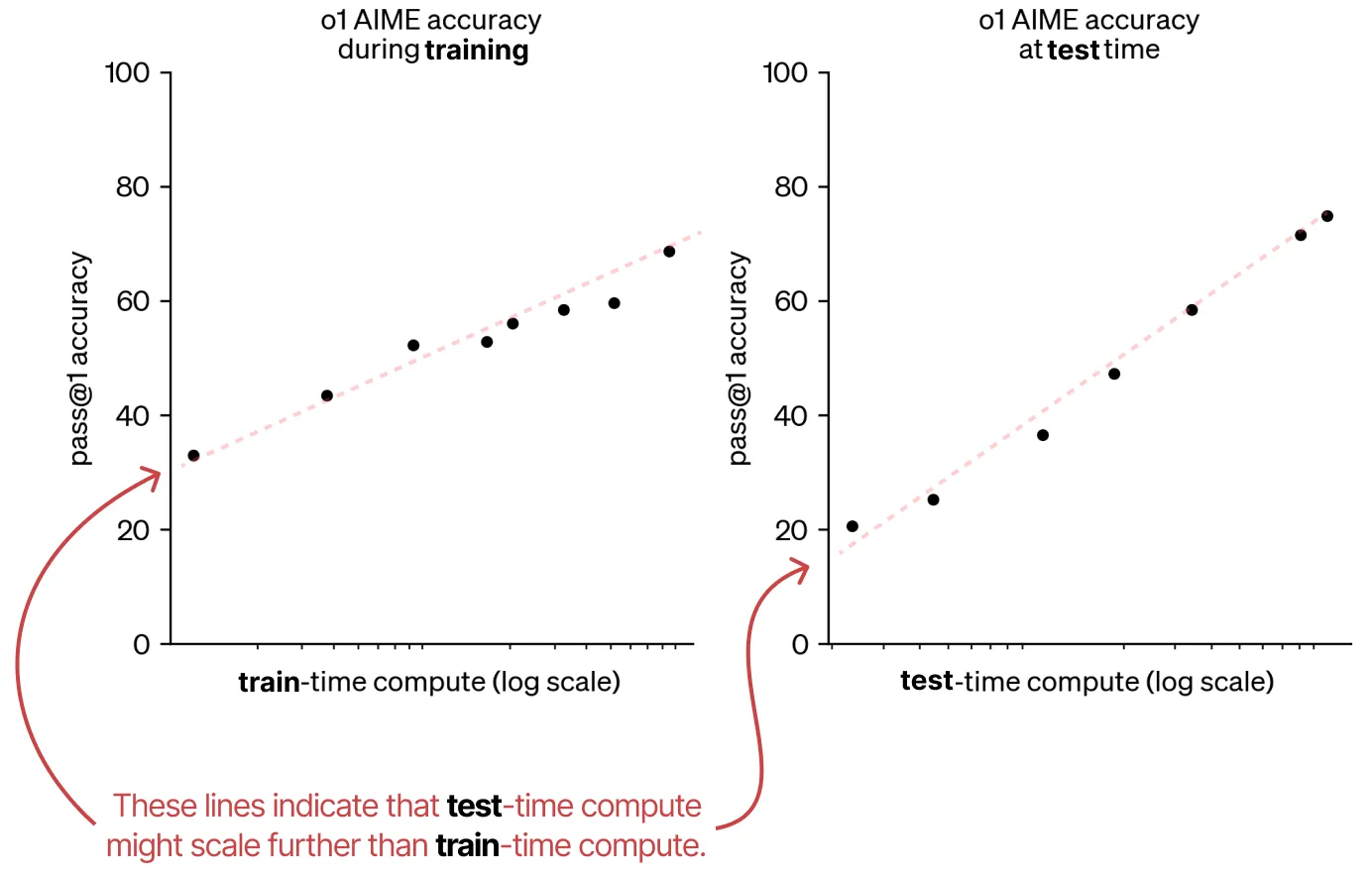
来自“学习如何推理的 LLM”一文的注释图:红色虚线显示了 OpenAI 提出的新范式可能是推理时计算。
这张图展示了 训练时间计算(train-time compute)和测试时间计算(test-time compute) 对模型 pass@1 准确率(accuracy) 的影响,具体来说,它强调了 测试时间计算可能比训练时间计算更有利于扩展模型性能。
左图:训练时间计算 vs. 准确率
- X 轴(横轴):训练时间计算(log scale,指数刻度)。
- Y 轴(纵轴):pass@1 准确率(即模型在一次尝试中得到正确答案的概率)。
- 黑色点 代表不同计算量下的模型表现,粉色虚线展示了大致的趋势。
- 可以看到,随着 训练计算量的增加,准确率逐渐提高,但增长趋势相对平稳。
右图:测试时间计算 vs. 准确率
- X 轴(横轴):测试时间计算(log scale)。
- Y 轴(纵轴):pass@1 准确率。
- 同样,黑色点代表不同计算量下的模型表现,粉色虚线展示了大致的趋势。
- 这里可以看到,随着 测试时计算量增加,模型的准确率增长更显著,甚至超过了训练计算量的效果。
因此,他们认为,推理时计算的扩展可能代表着新的研究范式。
其次,一篇名为《Scaling Scaling Laws with Board Games》的论文研究了 AlphaZero 在不同计算量下玩 Hex 游戏的表现。
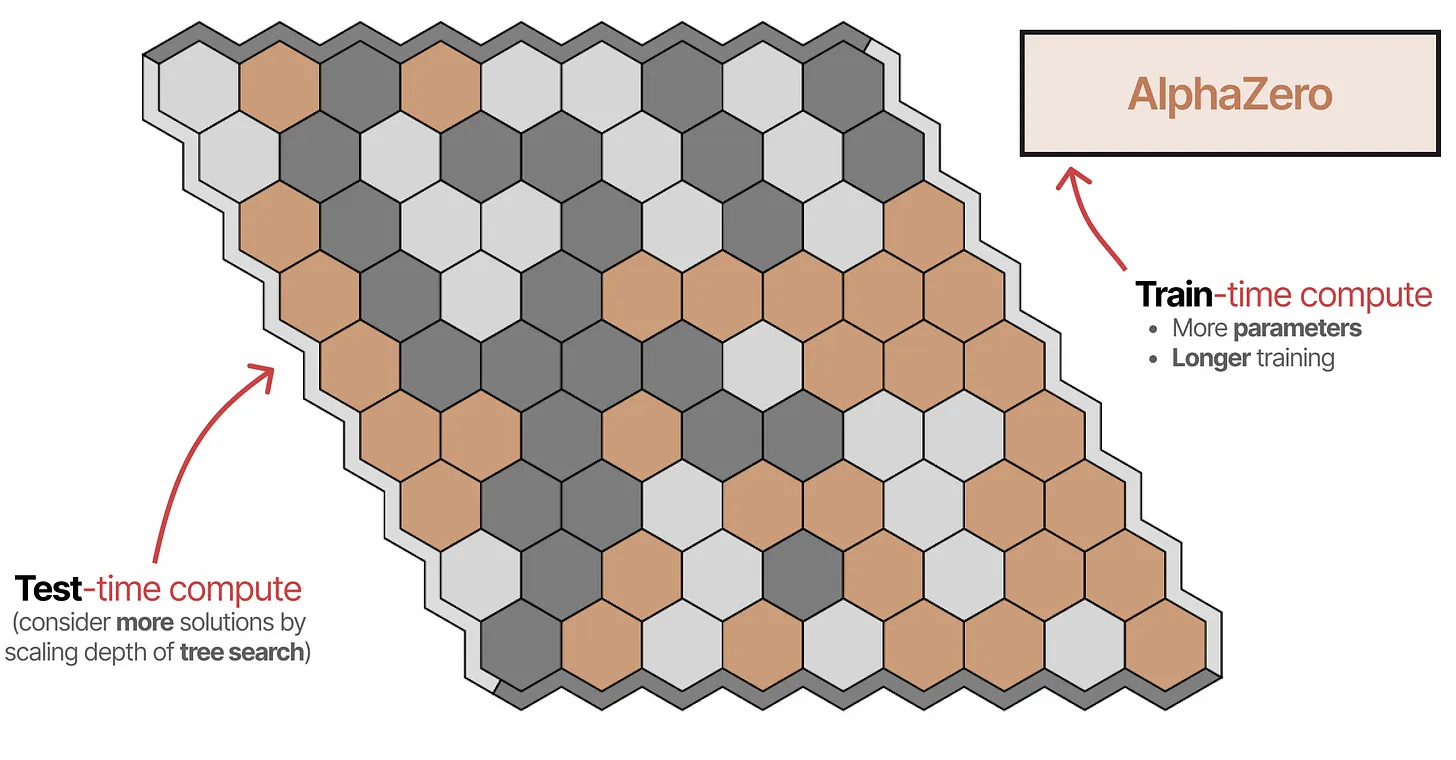
来自“Scaling Scaling Laws with Board Games”一文的注释图:该图展示了他们如何构建不同规模的训练时计算和推理时计算。- AlphaZero 是 DeepMind 开发的一个 强化学习(Reinforcement Learning, RL) 训练的 AI。
- 该算法通过 自我对弈(self-play) 训练,无需人为规则输入,即可掌握围棋、国际象棋、将棋等游戏。
- 它结合了 神经网络预测 和 蒙特卡洛树搜索(MCTS, Monte Carlo Tree Search) 来进行决策。
这张图片展示了 AlphaZero 算法 在训练阶段(train-time compute)和测试阶段(test-time compute)计算资源的不同应用。主要强调了:
- 训练时:依赖于更多参数和更长的训练时间来优化模型。
- 测试时:依靠 更深入的树搜索(tree search) 来提升决策能力。
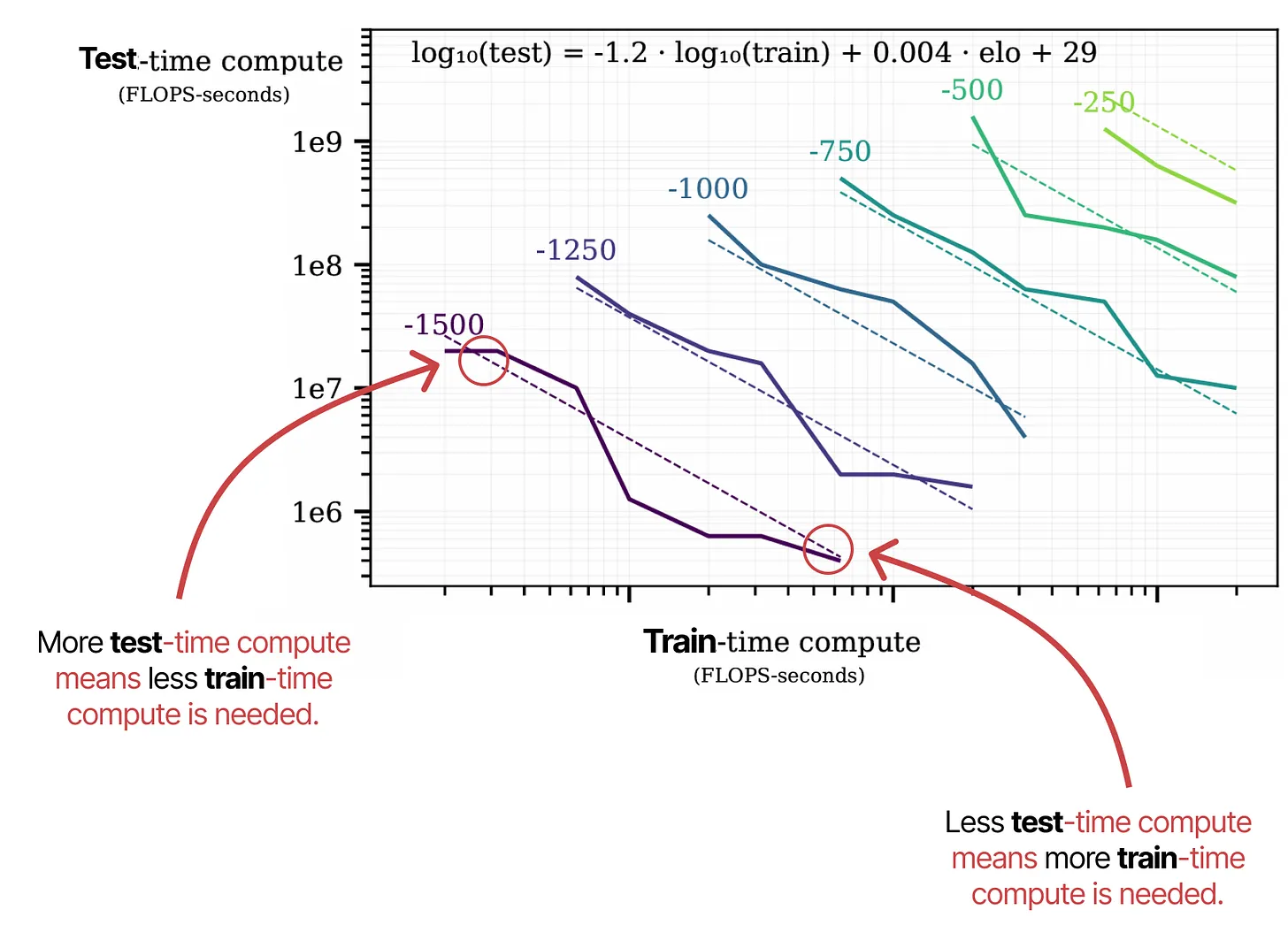
来自“Scaling Scaling Laws with Board Games”一文的注释图:该图展示了训练时计算与推理时计算之间的关系。
研究结果表明,训练时计算和推理时计算紧密相关。每条虚线表示达到特定 ELO 分数所需的最小计算量。
1. 坐标轴含义
- X 轴(横轴):训练时计算量(Train-time Compute,FLOP-seconds)
- Y 轴(纵轴):推理时计算量(Test-time Compute,FLOP-seconds)
- 对数刻度(log scale):计算量的增长呈指数级,而不是线性增长。
2. 关键数据趋势
- 不同颜色的曲线分别表示不同的 ELO 分数水平(-1500、-1250、-1000、-750、-500、-250)。
- 虚线和实线:
- 虚线 表示某个 ELO 分数下的最优计算边界。
- 实线 代表实际数据趋势。
训练计算和推理计算可以互相替代
- 如果推理计算量增加(左上区域),那么所需的训练计算量减少。
- 如果训练计算量增加(右下区域),那么所需的推理计算量减少。
- 两者呈现负相关关系。
低训练计算 vs. 高推理计算
- 在 训练计算较少 的情况下(如左侧的红色圈),模型仍然可以达到相同的 ELO 水平,但需要 在推理时增加计算量(如更深的搜索树、更长的思考路径)。
高训练计算 vs. 低推理计算
- 在 训练计算充足 的情况下(如右侧的红色圈),模型可以减少推理计算需求,即 即使使用较少的搜索深度,仍然能获得较高的性能。
公式解释
- 公式:
$$
\log_{10}(\text{test compute}) = -1.2 \cdot \log_{10}(\text{train compute}) + 0.004 \cdot \text{elo} + 29
$$ - 这说明:
- 训练计算(train compute)增加时,推理计算(test compute)减少(系数 -1.2)。
- 更高的 ELO(更强的 AI)需要额外的计算(系数 0.004)。
- 公式:
随着推理时计算扩展类似于训练时计算,研究范式正朝着“推理”模型利用更多推理时计算的方向发展。通过这种范式转变,这些“推理”模型不再单纯关注训练时计算(预训练和微调),而是平衡训练与推理。
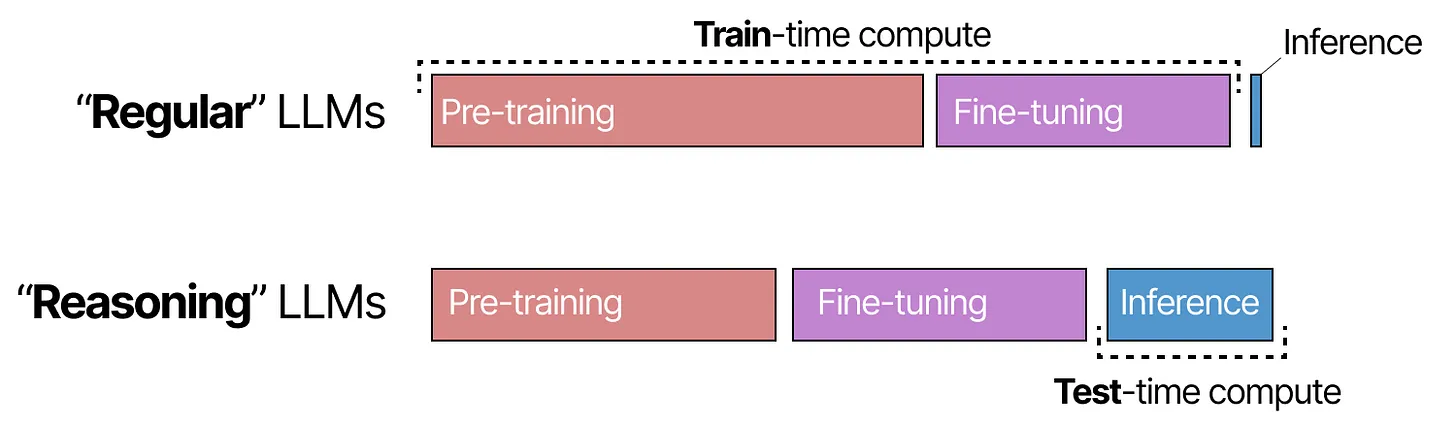
推理时计算甚至可以随长度扩展:
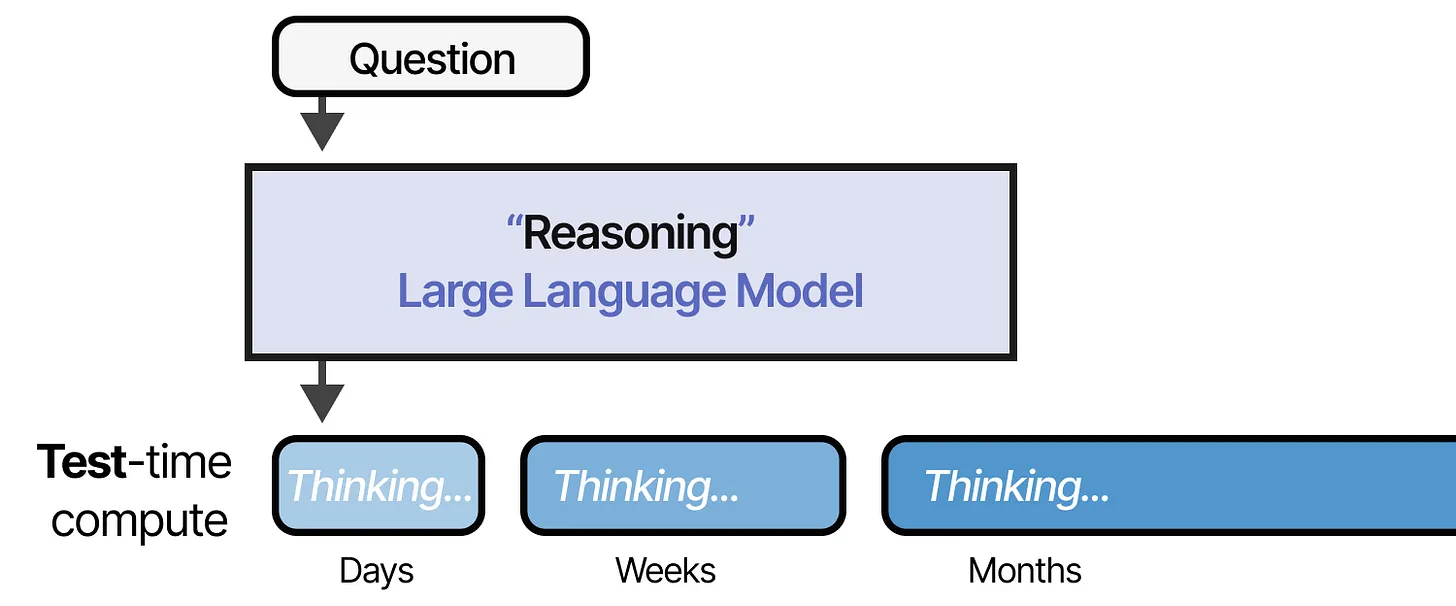
这是我们在 DeepSeek-R1 研究中也将探讨的内容!
📌 推理时计算的类别(Categories of Test-time Compute)
推理模型(如 DeepSeek-R1 和 OpenAI o1)的成功表明,在推理过程中,除了简单地“思考更长时间”之外,还有更多的优化技术。
在本文中,我们将探讨 推理时计算(Test-time Compute) 的多种实现方式,包括:
- 链式思维(Chain-of-Thought)
- 答案修订(Revising Answers)
- 回溯推理(Backtracking)
- 多样性采样(Sampling)
- 其他方法
总体而言,推理时计算可归纳为以下 两大类别:
基于验证器的搜索(Search against Verifiers)
- 通过 采样多个答案 并 选择最佳答案 来优化推理。
修改提议分布(Modifying Proposal Distribution)
- 通过训练 “思考”过程 来提高推理能力。Proposal Distribution(提议分布,指在模型生成答案时,对不同可能答案的概率分布进行调整)
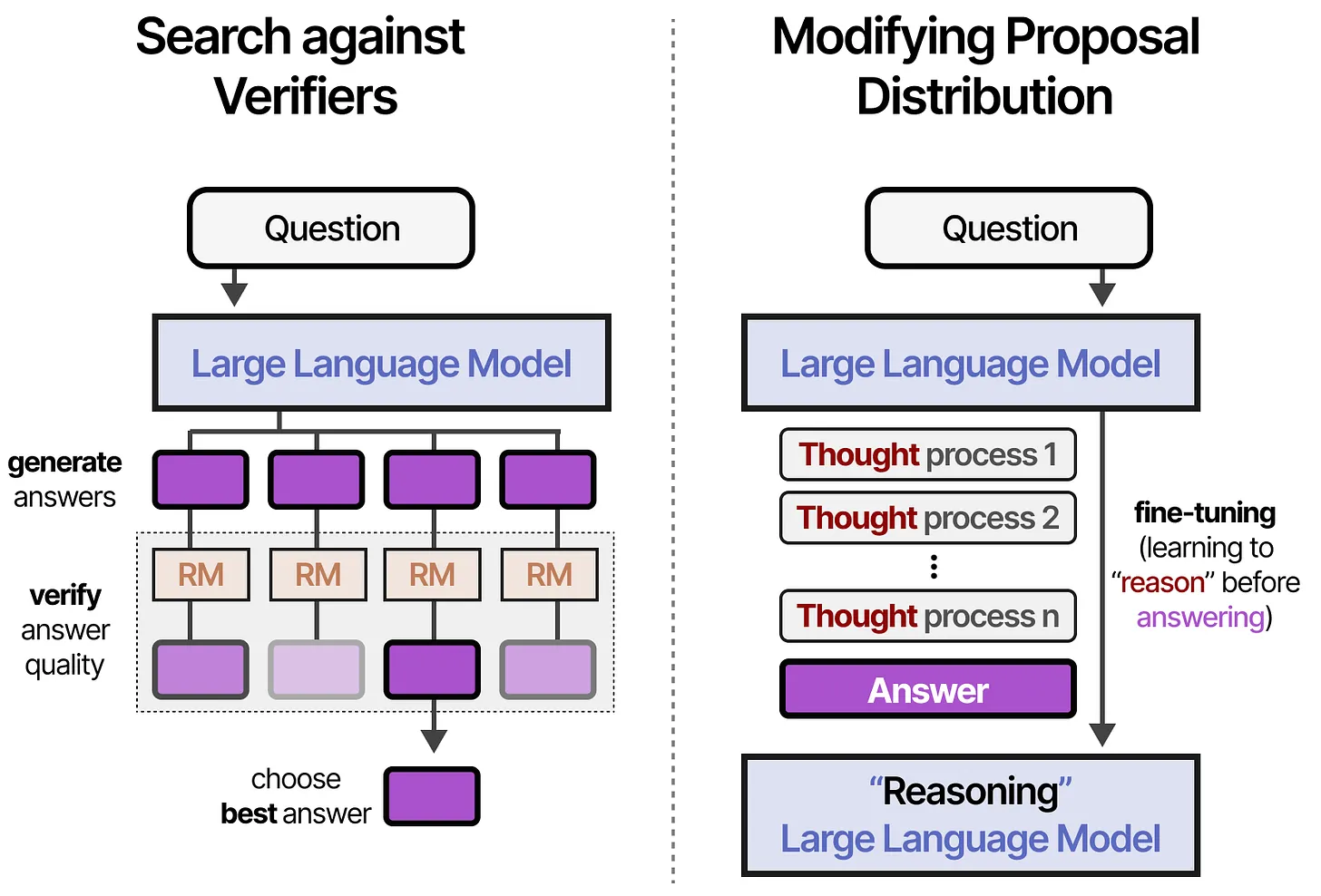
从本质上讲:
- 基于验证器的搜索 更关注 输出质量(Output-focused)。
- 修改提议分布 关注 输入结构(Input-focused)。
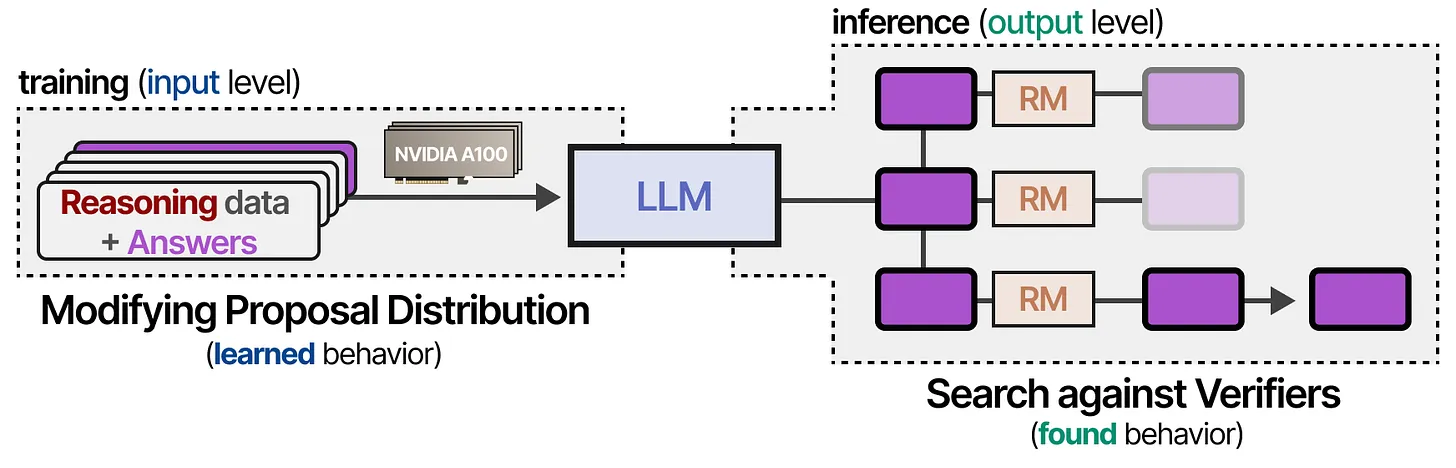
🔍 两种主要验证器类型
为了更好地筛选和评估推理答案,我们引入了两种 验证器(Verifiers):
结果奖励模型(Outcome Reward Models, ORM)
- 仅对最终答案进行评分,而不考虑推理过程。
过程奖励模型(Process Reward Models, PRM)
- 既评估最终答案,也对推理过程进行评分。
在接下来的部分,我们将详细探讨 如何将 ORM 和 PRM 应用于不同的验证方法!
顾名思义,结果奖励模型(Outcome Reward Model, ORM) 仅评估最终的答案质量,而不关注答案背后的推理过程:
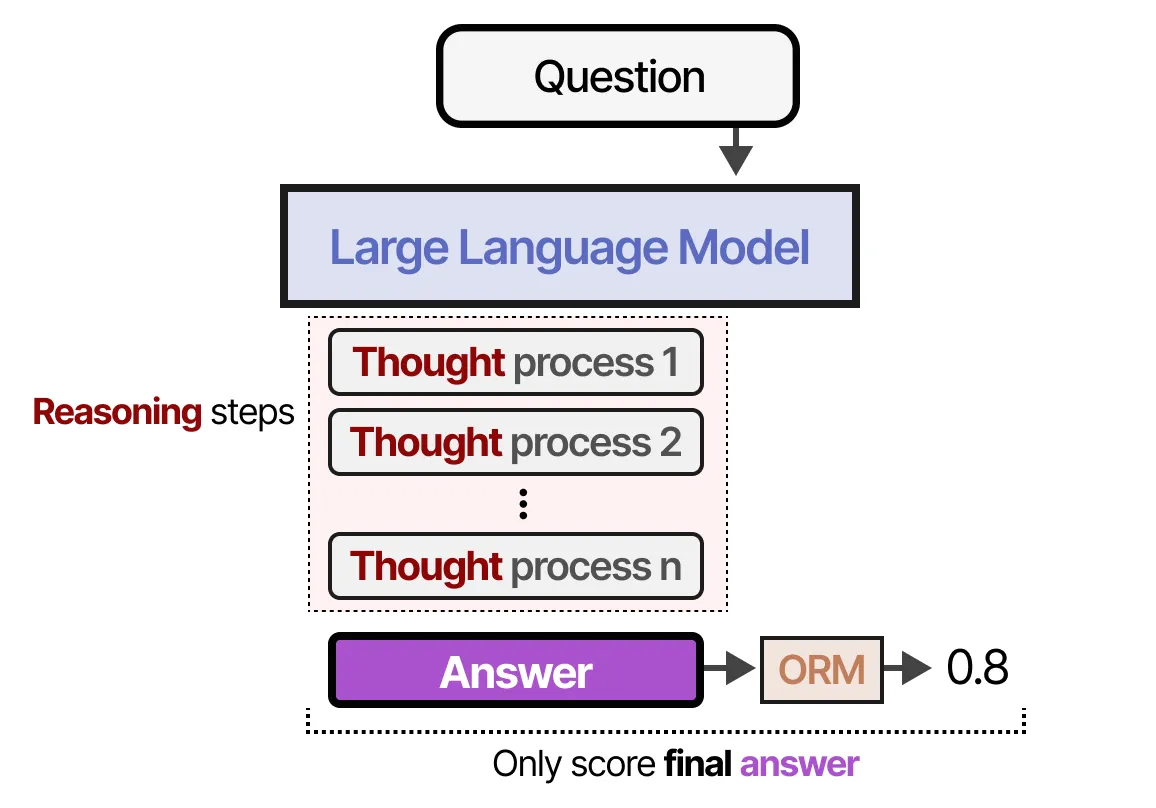
- ORM 只看最终输出,而不关心模型是如何得出这个答案的。
相比之下,过程奖励模型(Process Reward Model, PRM) 则会评估推理过程本身:
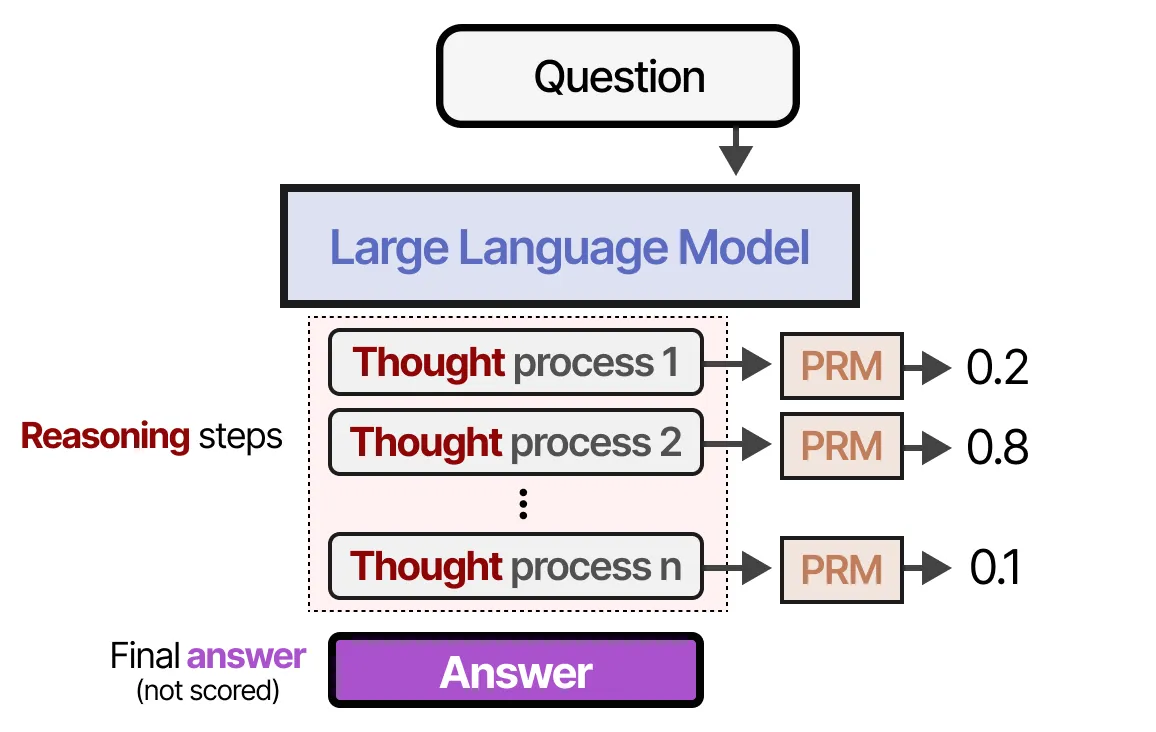
- PRM 既评估答案的正确性,也关注推理路径的合理性。
🧐 PRM 如何评估推理过程?
为了更清楚地说明推理步骤的重要性,让我们来看一个示例:
1 | 问题:某个方程的解是多少? |
在上述示例中,虽然最终答案(x = 5)是错误的,但 ORM 仅评估最终输出,不会关注中间的错误推理。
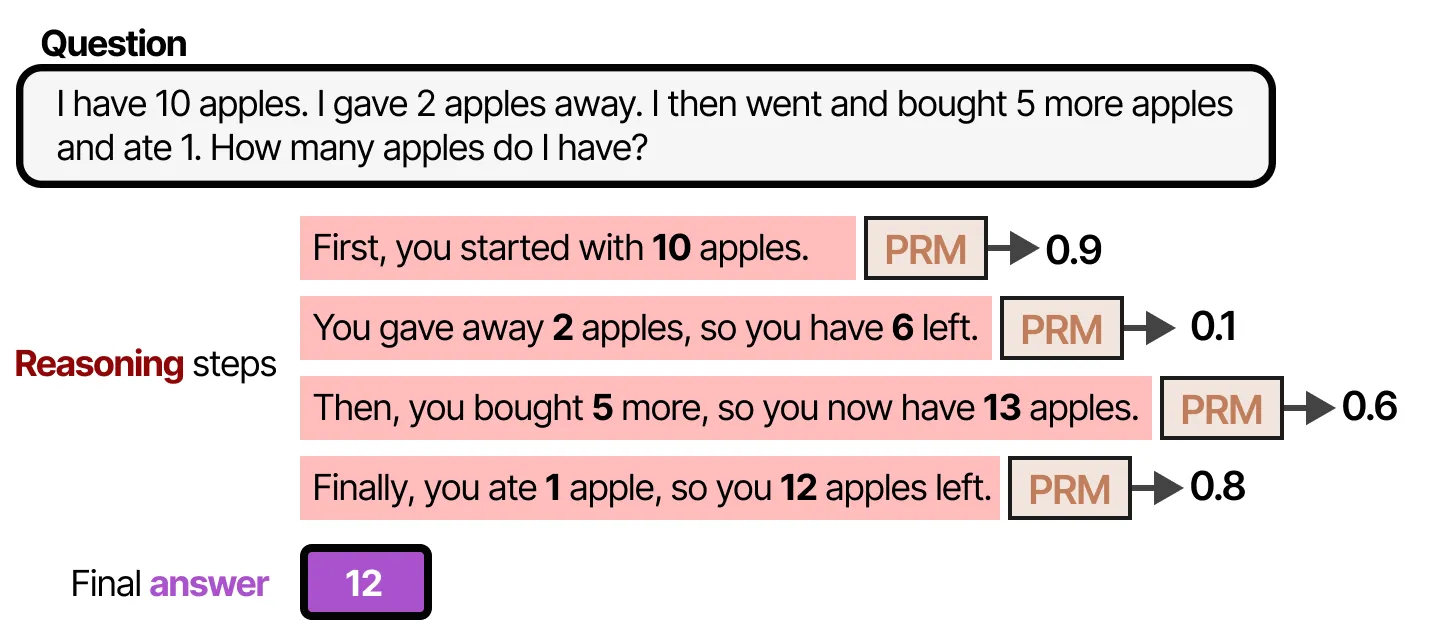
或者在这个例子中,PRM 会发现 推理步骤 2 是错误的,并对此步骤给予低分,从而避免错误答案的出现。
🔍 ORM vs. PRM 在推理中的应用
现在你已经掌握了 结果奖励模型(ORM) 和 过程奖励模型(PRM) 之间的区别,我们接下来探讨如何将它们应用于各种 验证技术(Verification Techniques)。
📌 基于验证器的搜索(Search against Verifiers)
推理时计算的第一大类别是 基于验证器的搜索,它通常包含两个步骤:
- 生成多个推理过程和答案样本
- 使用验证器(奖励模型)对生成的输出进行评分
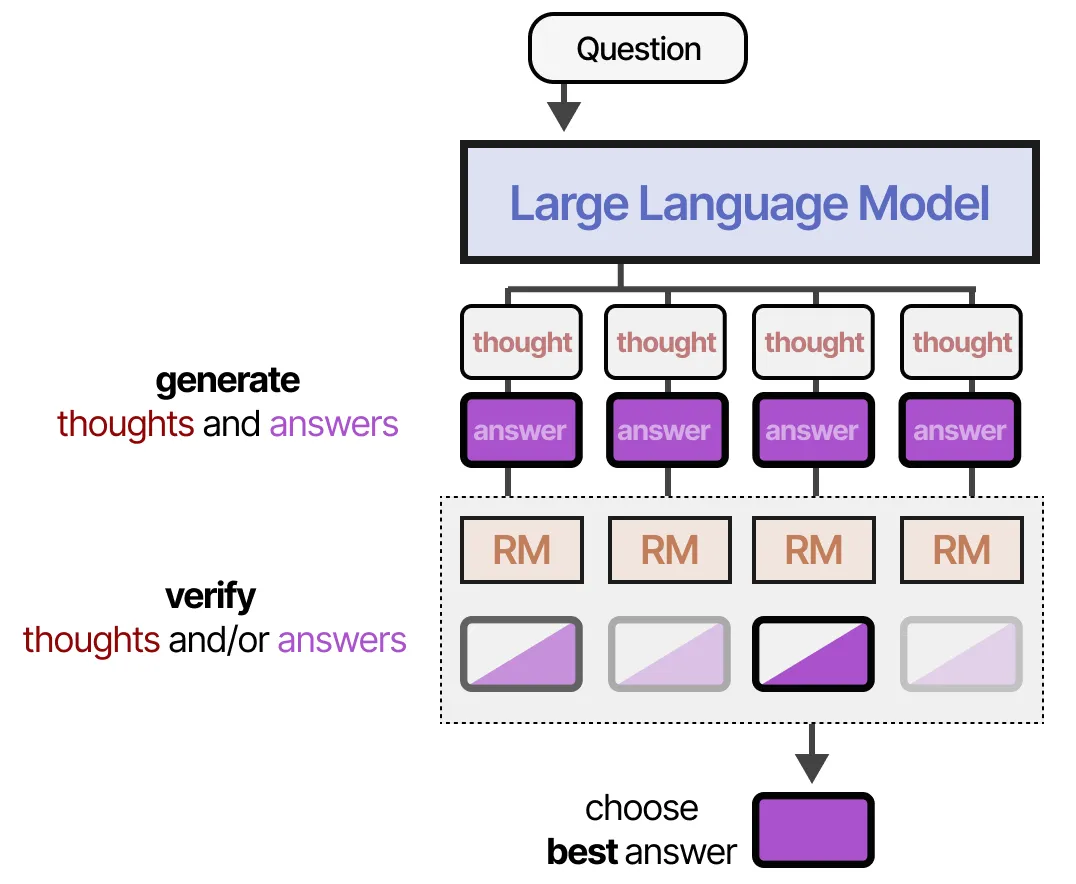
🤖 验证器的作用
验证器通常是一个大型语言模型(LLM),经过微调以评估结果(ORM)或过程(PRM)。 使用验证器的一个主要优势是,无需重新训练或微调用于回答问题的大型语言模型(LLM),仅通过评分机制选择最佳答案。
✅ 多数投票法(Majority Voting)
最简单的方法是 不使用奖励模型或验证器,而是执行 多数投票(Majority Voting)。
📌 方法: 让 LLM 生成多个答案,选择出现次数最多的答案作为最终答案。
📌 示例:
1 | Q: 15 × 3 = ? |
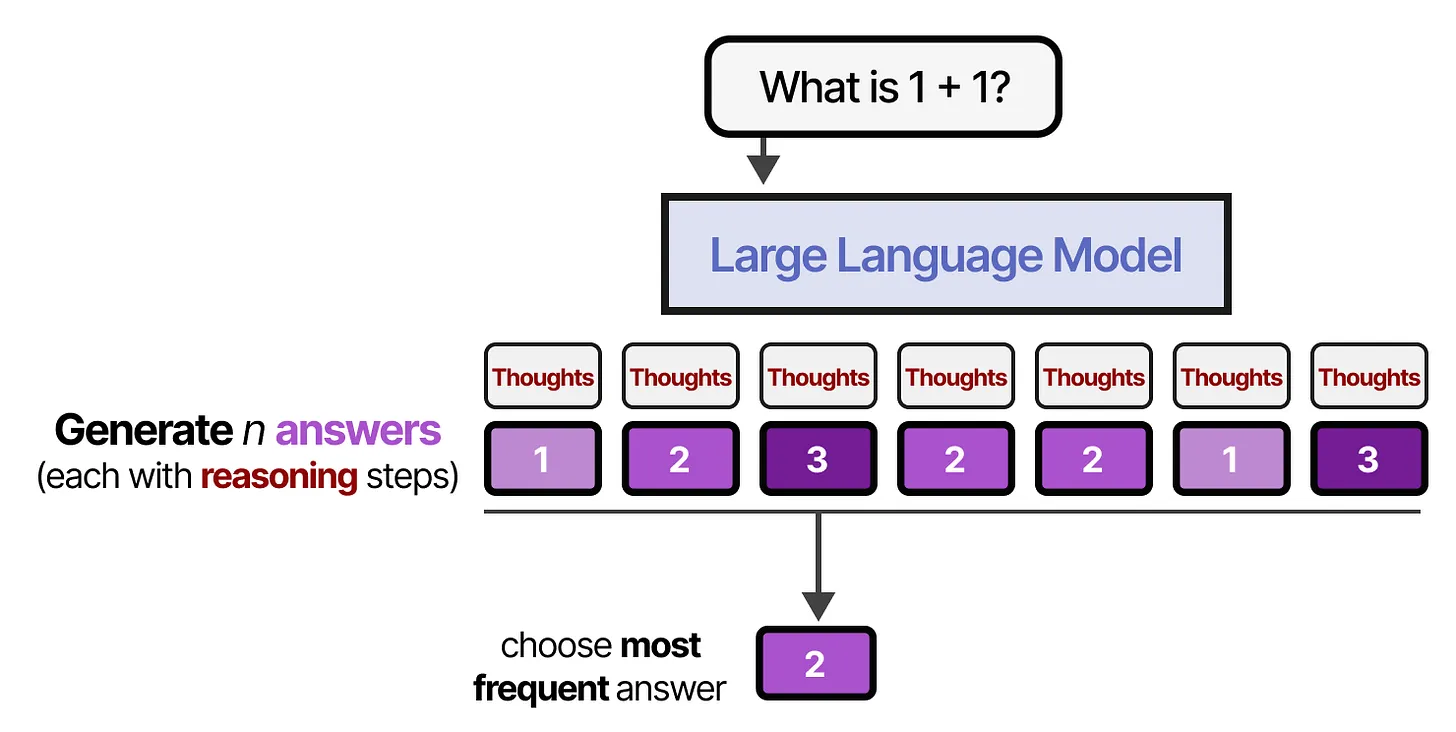
这种方法也称为 自一致性(Self-Consistency),强调 生成多个答案和推理步骤 的重要性。
🔢 Best-of-N 采样法(Best-of-N Samples)
Best-of-N 采样是第一个涉及验证器(Verifier)的方法,它的基本思想是生成 N 个样本答案,然后使用 奖励模型(Reward Model, RM) 对这些答案进行评分,并选择得分最高的答案。
📌 步骤:
- 生成多个答案(使用较高或者不同的温度参数生成 N 个样本)。
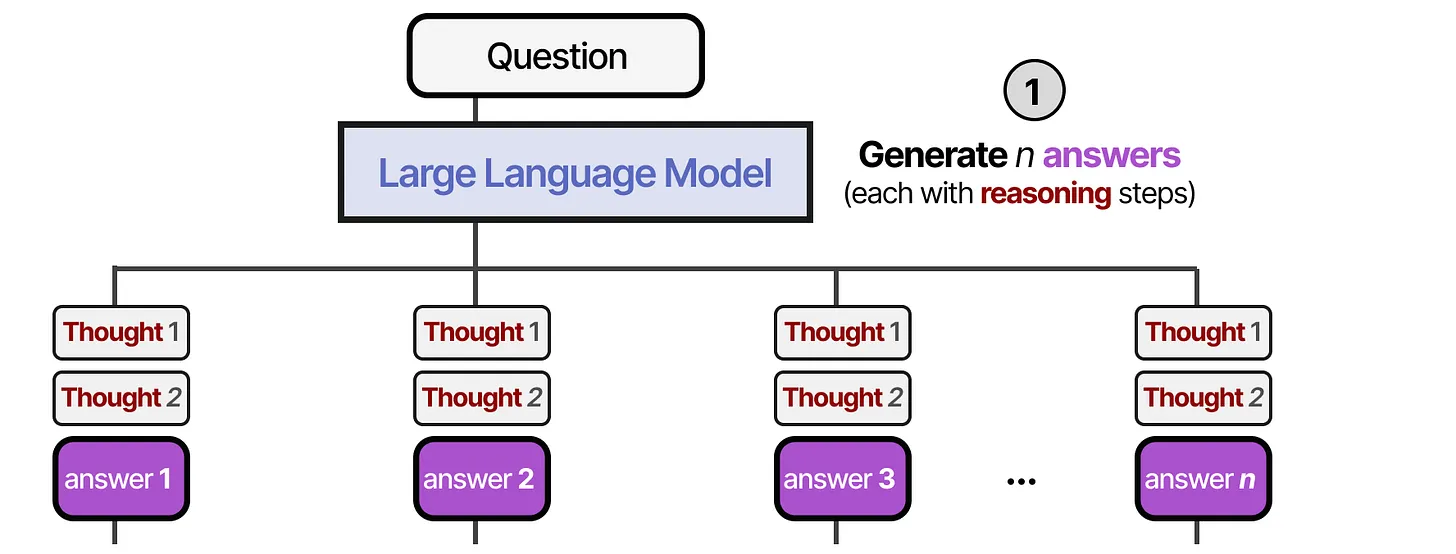
- 结果奖励模型(ORM, Outcome Reward Model),每个答案都会通过 ORM 进行评分。选取得分最高的答案作为最终输出。
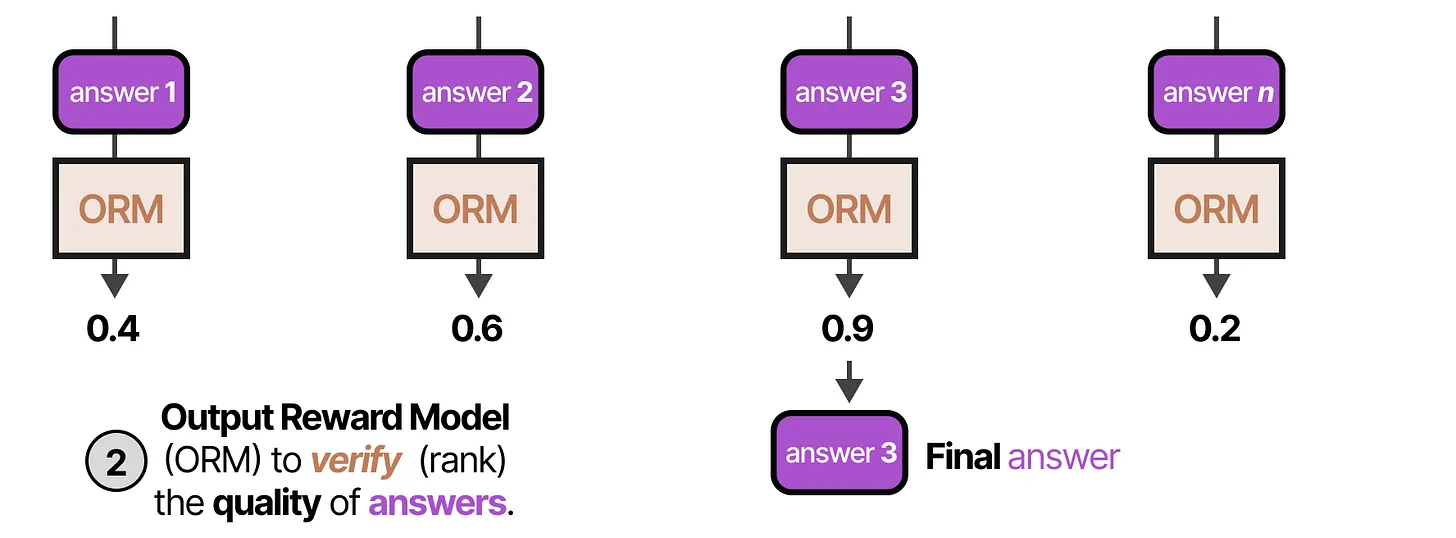 📌 示例:
📌 示例:
1 | Q: 8 + 5 = ? |
📌 进一步优化:
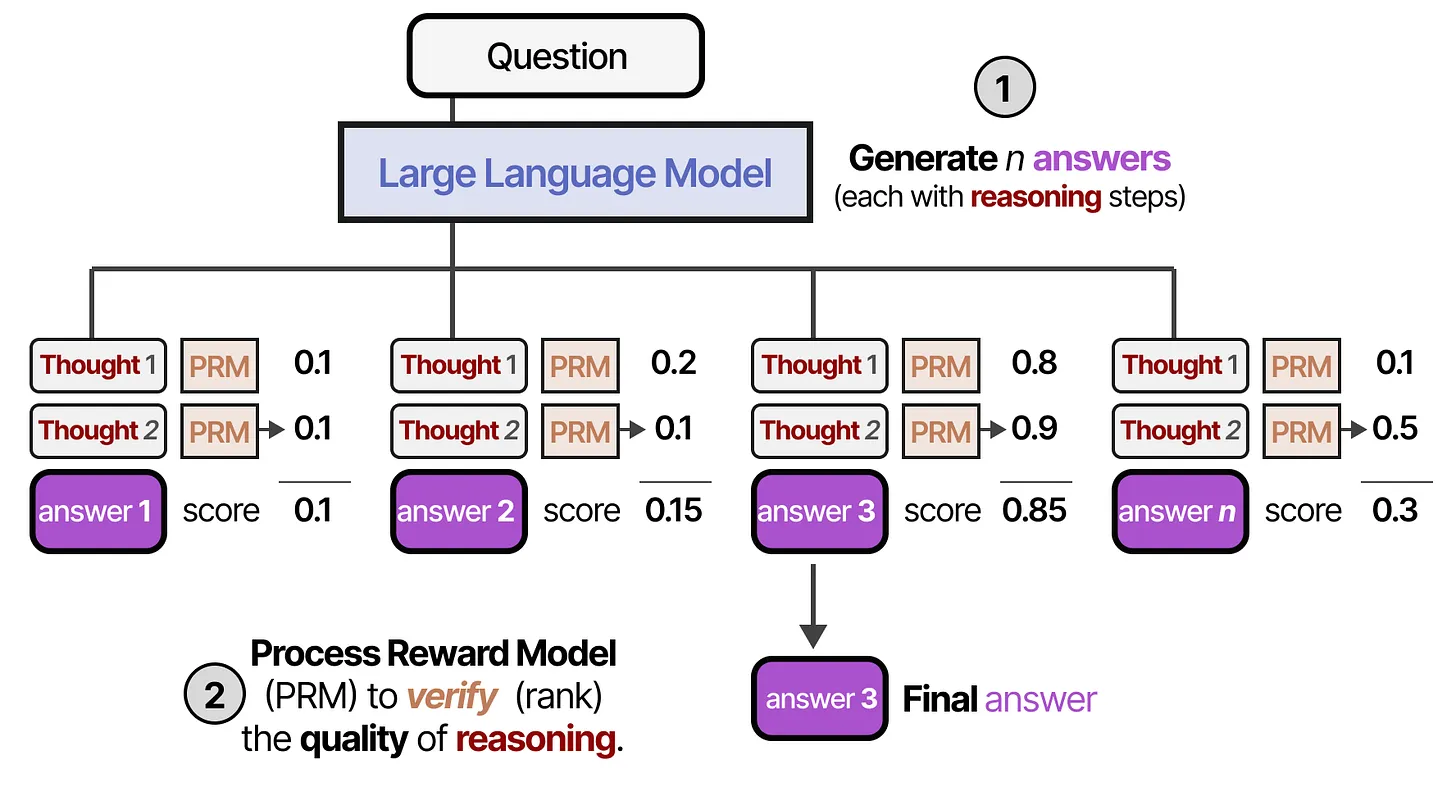
- 若使用 PRM,则不只评估答案,还评估整个推理过程。与仅评估最终答案的结果奖励模型(ORM)不同,过程奖励模型(PRM)会评估推理过程的质量。PRM 关注推理的每个步骤,确保推理过程合理、连贯,并最终选择总评分最高的候选答案。
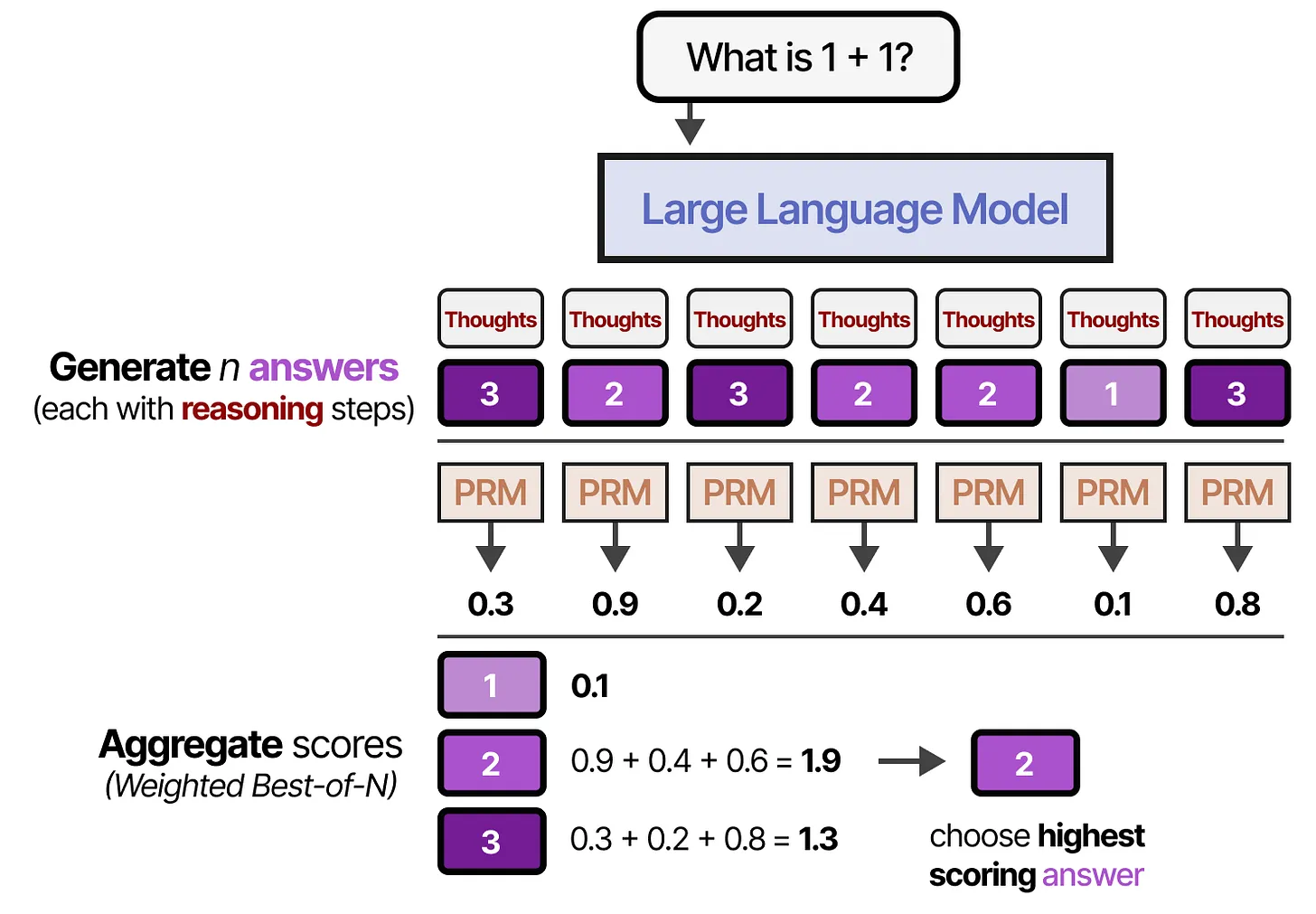
- 加权 Best-of-N 采样(Weighted Best-of-N samples):结合 ORM 和 PRM 两种验证方式,我们可以对所有候选答案进行加权评分,并选择总权重最高的答案。这种方法称为 加权 Best-of-N 采样(Weighted Best-of-N samples):。
🚀 使用过程奖励模型(PRM)的束搜索(Beam Search)
在生成答案及其中间推理步骤的过程中,我们可以使用 束搜索(Beam Search) 进一步优化推理路径。
📌 束搜索的核心思想:
- 在推理过程中,生成多个可能的推理路径(称为“束”)。
- 使用 过程奖励模型(PRM, Process Reward Model) 对每条路径进行评分。
- 类似于 Tree of Thought 方法,始终保留得分最高的 前 3 条推理路径,并在推理过程中持续跟踪这些路径。
- 如果某条路径的得分较低(PRM 评分低),则提前停止该推理路径,以避免不必要的计算开销。
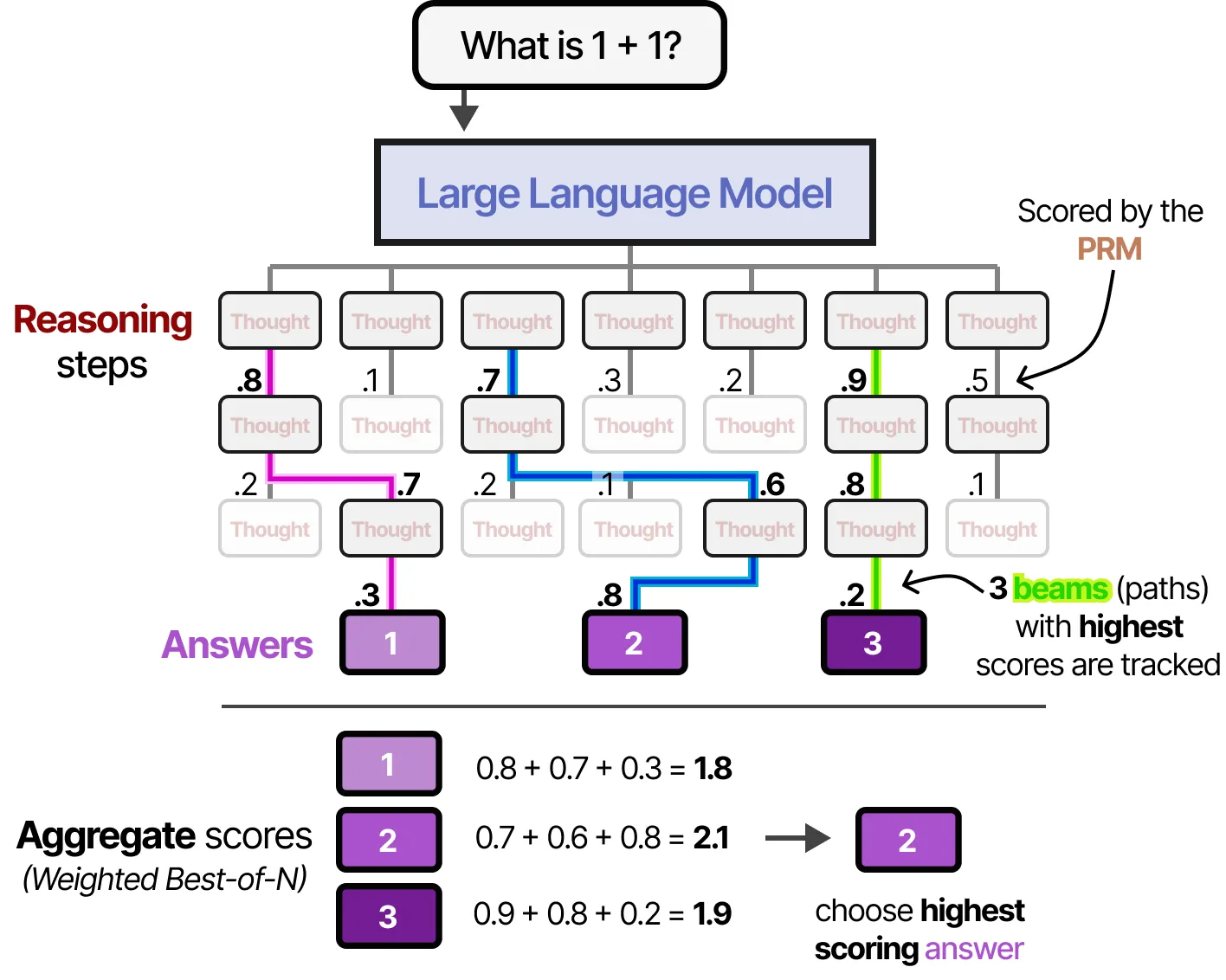
📌 优化后的答案筛选方式:
最终,生成的所有答案将使用 Best-of-N 采样 方法进行加权评分,确保选出最佳推理路径的最终答案。
🚀 优势:
- 避免计算资源浪费,快速淘汰低质量推理路径。
- 结合 PRM,可以确保模型的推理过程更连贯、更符合逻辑。
- 通过 Best-of-N 方法进一步优化答案质量,使最终答案更加可靠。
🎲 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)
蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)是一种常用于决策树搜索的算法,在 LLM 的推理优化中也可以采用该方法。MCTS 通过四个步骤来优化推理路径:
📌 主要步骤:
- 选择(Selection): 根据预定义的公式,从当前搜索树中选择一个叶节点 进行扩展。
- 扩展(Expand): 在所选叶节点的基础上 创建新的子节点,以探索更多可能的推理路径。
- 模拟(Rollouts): 通过随机生成新的推理路径,持续扩展节点,直到达到终点(即得到最终答案)。
- 回溯(Backpropagation): 根据最终输出结果 更新父节点的评分,从而优化未来的搜索决策。
在大语言模型(LLM)的推理过程中,我们通常希望找到最佳的推理路径,使其最终生成的答案最优。但在这个过程中,需要在 探索(Exploration) 和 利用(Exploitation) 之间取得平衡:
- 利用(Exploitation):选择当前看起来最优的路径,以利用已知的高质量推理步骤。
- 探索(Exploration):选择访问次数较少的路径,以发现可能更优的推理步骤。
选择分数(Selection Score)
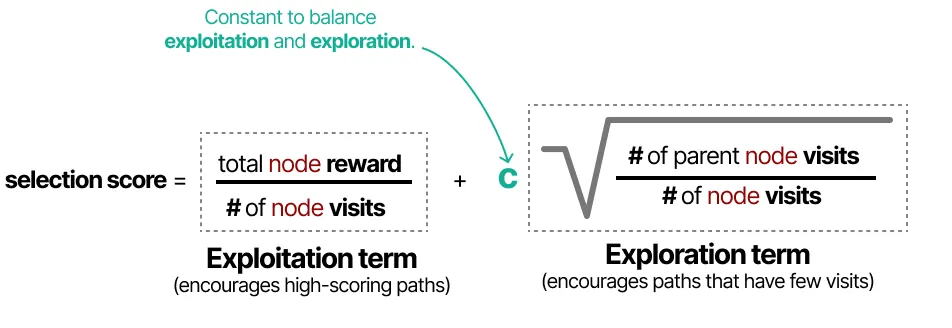
在选择推理路径时,我们使用 选择分数(Selection Score) 计算每个推理步骤(即树的节点)的优先级,公式如下:
$$
\text{Selection Score} = \frac{\text{Total Node Reward}}{\text{Number of Node Visits}} + C \times \sqrt{\frac{\text{Number of Parent Node Visits}}{\text{Number of Node Visits}}}
$$
其中:
第一项:$$\frac{\text{Total Node Reward}}{\text{Number of Node Visits}}$$(利用项,Exploitation Term)
- Total Node Reward:该节点累计获得的奖励值(表示其历史表现)。
- Number of Node Visits:该节点被访问的次数。
- 这项计算的是该节点的 平均奖励值,高奖励的节点会被优先选择。
第二项:$$C \times \sqrt{\frac{\text{Number of Parent Node Visits}}{\text{Number of Node Visits}}}$$(探索项,Exploration Term)
- # of Parent Node Visits:父节点被访问的次数。
- # of Node Visits:当前节点被访问的次数。
- C:一个超参数,控制探索与利用的平衡。
- 这项鼓励探索访问次数较少的节点,以防止过早陷入局部最优解。
总结:
- 第一项(Exploitation Term) 让算法倾向于选择 历史表现较好的路径。
- 第二项(Exploration Term) 让算法倾向于 探索访问较少的路径,避免陷入局部最优。
- 参数 C 控制这两者的平衡。
2. 选择(Selection)与扩展(Expand)
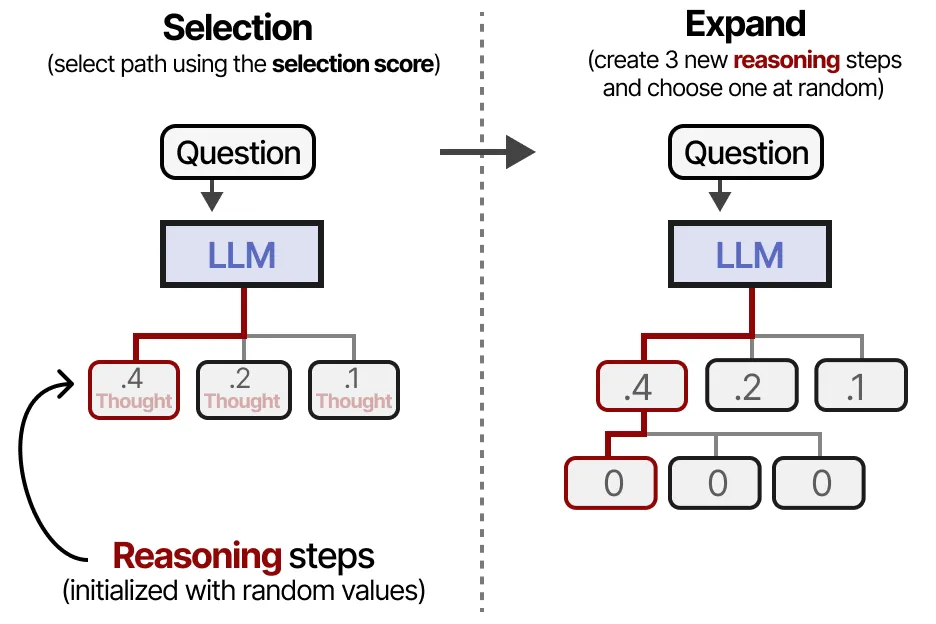
这一阶段,我们使用 选择分数 来决定哪条推理路径值得继续扩展:
(1)选择(Selection)
- 输入:问题(Question)
- LLM 生成多个推理步骤(Reasoning Steps)
- 例如,在图片中,LLM 生成了 3 个推理步骤:
- Thought 1(评分 0.4)
- Thought 2(评分 0.2)
- Thought 3(评分 0.1)
- 例如,在图片中,LLM 生成了 3 个推理步骤:
- 使用选择分数(Selection Score)选择最优路径(随机初始化)
- 在示例中,评分最高的 Thought 1(0.4) 被选中。
(2)扩展(Expand)
- 在选中的推理路径上,生成新的推理步骤
- 这些新推理步骤的初始值设为 0,表示它们还没有经过评估。
这个过程类似于 MCTS 的拓展(Expansion)阶段,即:
- 选择当前最优路径(使用 选择分数)。
- 在该路径下,扩展新的推理步骤(未评分的子节点)。
3. Rollouts(模拟)与 Backpropagation(反向传播)
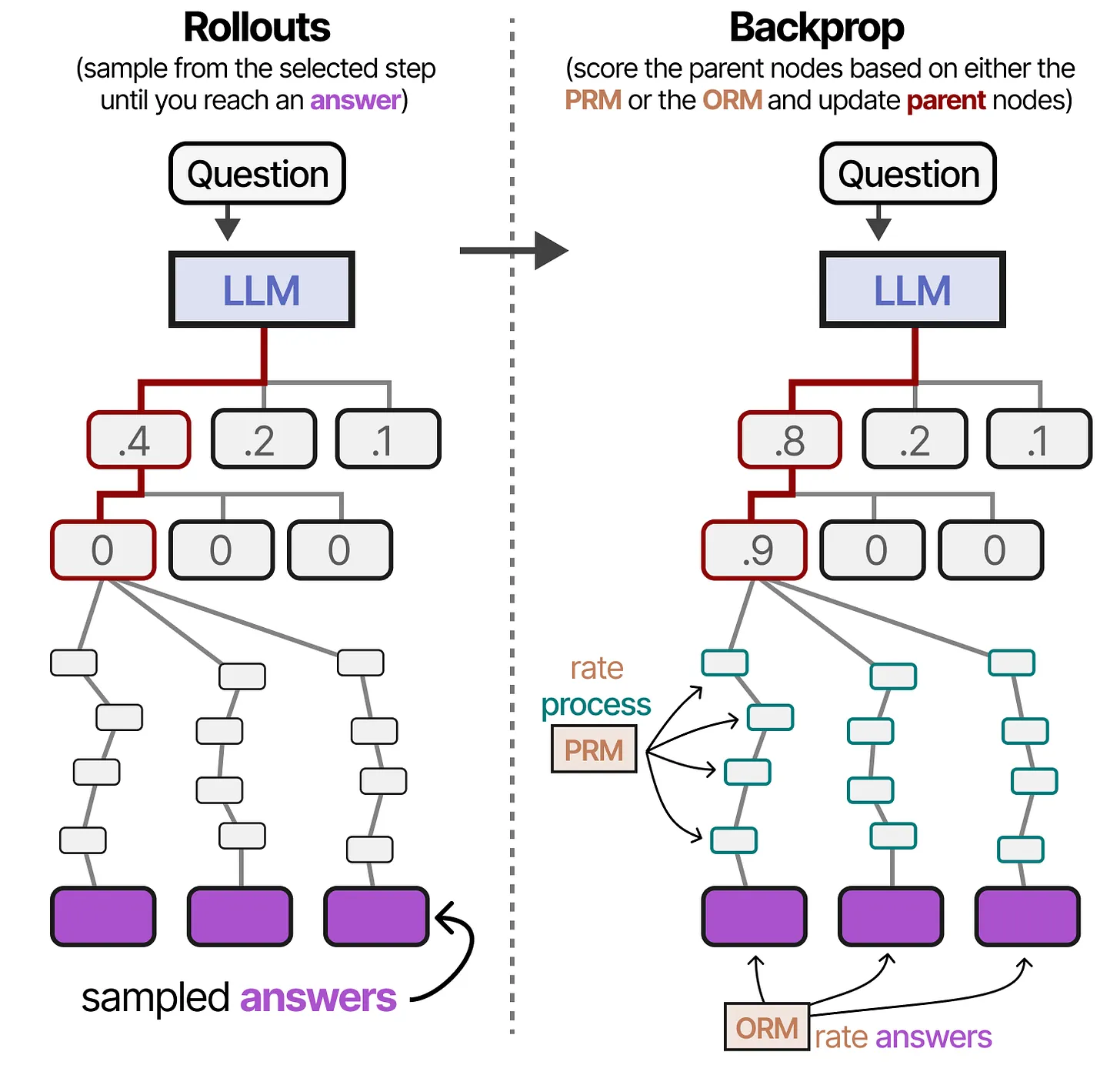
一旦扩展了推理步骤,我们需要继续探索,并利用 模拟(Rollouts) 和 反向传播(Backpropagation) 来优化整个搜索过程。
(3)Rollouts(模拟)
- 选定路径后,我们继续展开推理步骤,直到 生成最终答案。
- 这个过程类似于 在 MCTS 中随机模拟游戏到结束:
- 我们从当前节点出发,进行一系列推理,直到模型生成最终的答案。
- 在图片中,我们沿着 Thought 1(0.4) 继续展开推理步骤。
- 这些推理步骤最终会 生成多个答案(图片中紫色框)。
(4)Backpropagation(反向传播)
- 通过对 最终答案 进行评分,我们可以更新前面所有参与推理的节点分数:
- PRM(Process Reward Model):对推理步骤本身进行评分,衡量其合理性。
- ORM(Output Reward Model):对最终答案进行评分,衡量其正确性。
- 这些评分 向上传播,更新 所有经过的节点 的奖励值。
- 例如:
- 在图片中,最终答案的评分导致 Thought 1 的评分从 0.4 提高到 0.8。
- 进一步向上传播,使得 父节点的选择分数也随之更新。
这个过程保证了:
- 较好的推理路径会逐渐获得更高的分数,提高被选中的概率。
- 较差的推理路径会被逐渐淘汰,避免浪费计算资源。
📌 修改提议分布(Modifying Proposal Distribution)
修改提议分布(Modifying Proposal Distribution)
在大语言模型(LLM)的推理过程中,我们可以通过修改提议分布(Modifying Proposal Distribution)来优化模型的推理能力。这种方法的核心思想是:
- 不再单纯依赖模型搜索正确推理步骤(基于输出的优化),
- 而是让模型主动生成更优的推理步骤(基于输入的优化)。
换句话说,我们不是在输出结果后进行检验,而是直接修改模型在推理过程中如何选择 token,让它更倾向于选择能够引导推理的 token,而不是立即输出最终答案。修改了用于采样补全(completions)、思维(thoughts)或标记(tokens)的概率分布。这种方法可以让模型生成的答案更加准确、可解释,并且在面对复杂问题时更具有鲁棒性(robustness)。
1. 直接选择最高概率 Token(Greedy 选择)
在默认情况下,LLM 生成多个可能的 token 作为输出候选项,并根据其概率进行排序,最终选择最高概率的 token 进行输出。这种方法称为贪心选择(Greedy Selection)。
你可以想象,我们有一个问题(question)和一个用于采样 token 的概率分布(distribution)。常见的策略是选择得分最高的 token。
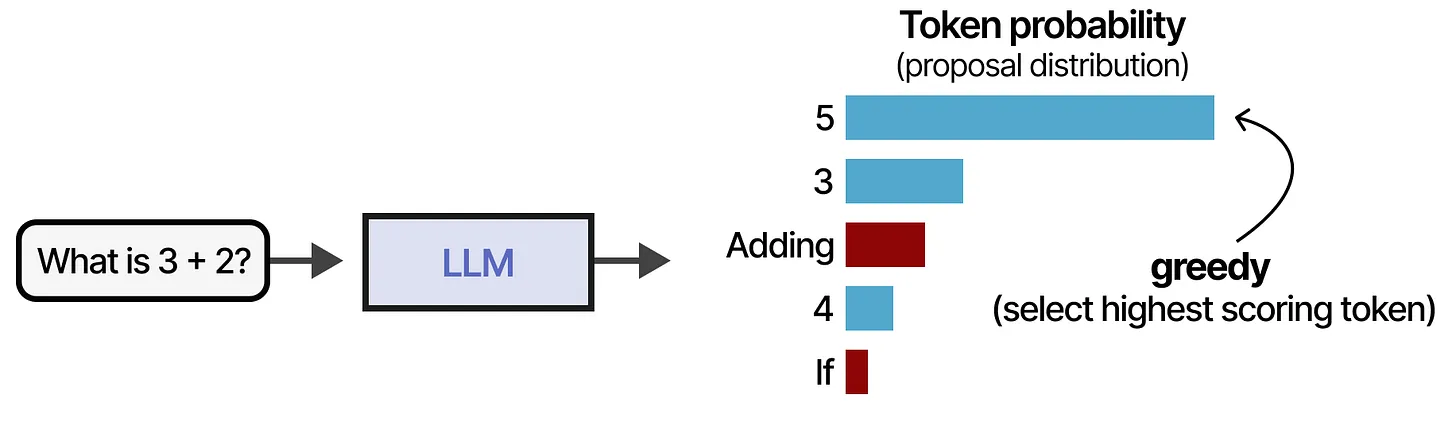
- 例如,给定问题
What is 3 + 2?,LLM 可能会生成如下候选 token:5(最高概率)3Adding4If
- 在贪心策略下,模型会直接选择
5作为最终答案,而不会进行推理。
这种方法虽然快速,但存在如下问题:
- 缺乏推理能力:模型可能直接输出错误答案,因为它没有进行推理。
- 可解释性差:对于复杂问题,用户无法理解模型是如何得出答案的。
2. 通过推理(Reasoning Before Answering)提高答案质量
然而,请注意上图中有一些标记(tokens被标红。这些token更有可能引导模型进入一个合理的推理过程。虽然选择贪心(greedy)策略下得分最高的 token 不一定是错误的,但选择那些能引导模型进入推理过程的 token,通常会得到更好的答案。
让 LLM 先进行推理,再给出答案,即:
- 选择推理 token(如
Adding) - 逐步生成推理过程,如:
Adding → 3 and 2 gives → 5If → 3 + 1 = 4, 4 + 1 = 5 → 5The total is → 5
- 通过推理链条逐步推导出
5,相比直接选择5,这种方法更加可解释,并且能在复杂问题上表现更好。
3. 通过修改提议分布(Re-Ranking Token Probabilities)引导推理过程
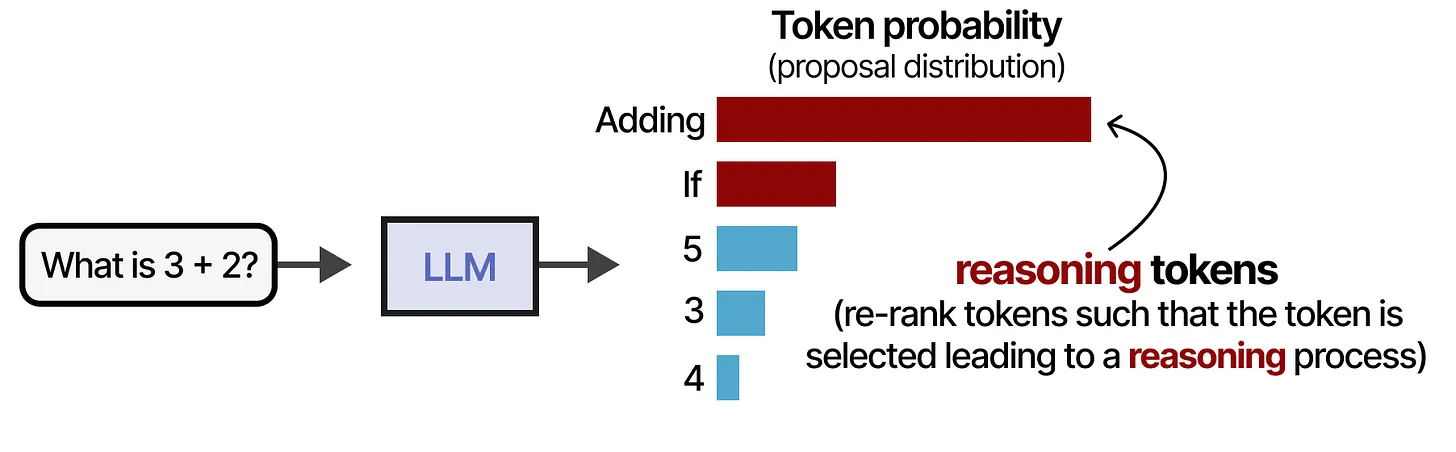
当我们修改提议分布(proposal distribution,即 token 的概率分布)时,实际上是在重新排序(re-rank)这个分布,使得“推理相关”的 token 被选中的概率更高。
在这种方法下,我们调整 LLM 的提议分布,使其更倾向于选择推理 token,而非直接选择答案:
- 默认情况下,
5具有最高概率,而Adding、If等推理 token 的概率较低。 - 通过修改提议分布,我们提高
Adding、If的概率,使模型倾向于进行推理。
4. 如何实现修改提议分布?
主要有两种方式:
- 通过 Prompt Engineering
- 修改 Prompt,引导模型生成推理步骤。
- 例如:
1
2Q: What is 3 + 2?
A: Let's think step by step.
- 训练模型更倾向于推理
- 在微调过程中,提供更多具有推理链的训练数据,让模型习惯生成推理 token。
总结
- 贪心选择(Greedy Selection):快速,但缺乏推理,可解释性差。
- 推理后回答(Reasoning Before Answering):提高答案质量和可解释性。
- 修改提议分布(Modifying Proposal Distribution):调整 token 选择的概率,使模型更倾向于选择推理 token,提高整体答案的合理性。
这种方法在数学计算、逻辑推理、法律推理等任务上尤为重要,使得 LLM 不仅能“答对”,还能“说明白”。
Prompting
随着我们使用 prompt engineering(提示工程)来改进输出,我们会通过更新提示(prompt)来尝试提升模型的表现。这个过程也可能推动模型去展示先前我们看到的一些reasoning(推理)过程。
1. 改变 Proposal Distribution
在更改 proposal distribution时,我们可以给模型提供示例(也叫做 in-context learning),让它在生成答案时模仿类似的推理风格。下面的图就展示了一个示例的情形:
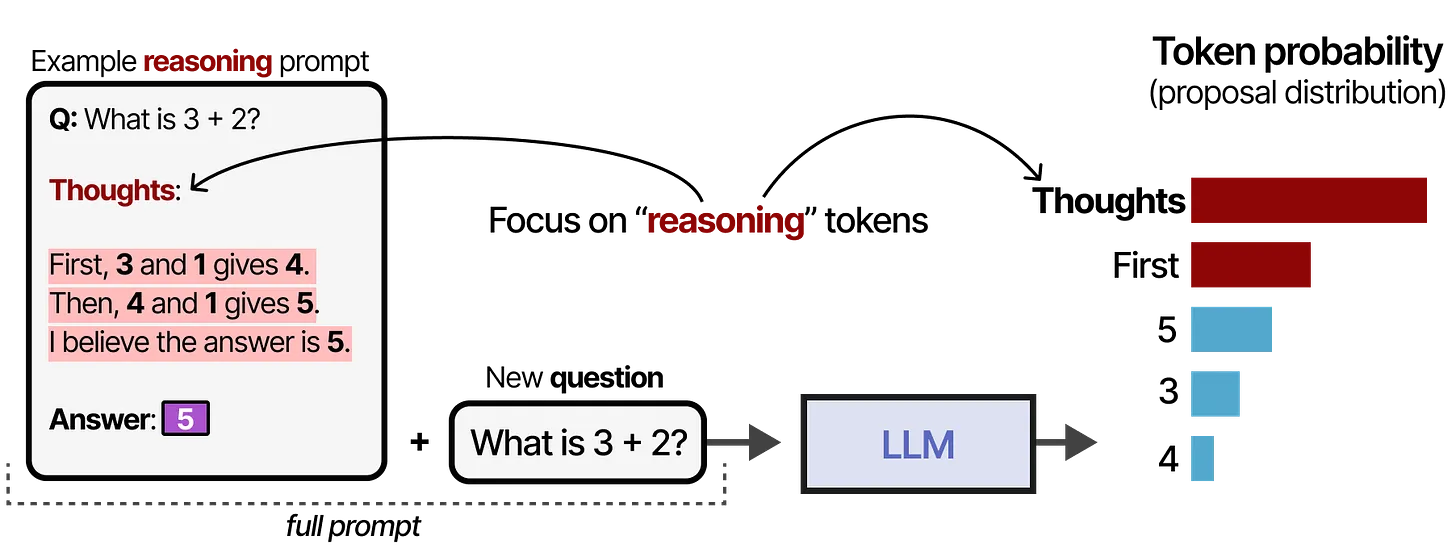
- 图示内容:左侧是一个简单的问题 “What is 3 + 2?”,模型内部用 “Thoughts” 表示隐藏的思考过程,比如:
- First, 3 and 1 gives 4.
- Then, 4 and 1 gives 5.
- I believe the answer is 5.
- Answer(答案):5
- 右侧用红色、蓝色等不同颜色的条形或方块表示推理过程的不同部分,示意有一部分属于隐藏的推理过程(红色),以及输出结果或若干中间步骤(蓝色)。
通过类似的示例,模型在推理时就可能模仿类似的格式来进行reasoning并给出最终答案。
2. “Let’s think step-by-step” 的影响
我们也可以通过在提示中直接使用 “Let’s think step-by-step” 来简化上述流程。这会改变模型的 proposal distribution,让 LLM(大型语言模型)倾向于在回答之前分步骤思考。如下图所示:
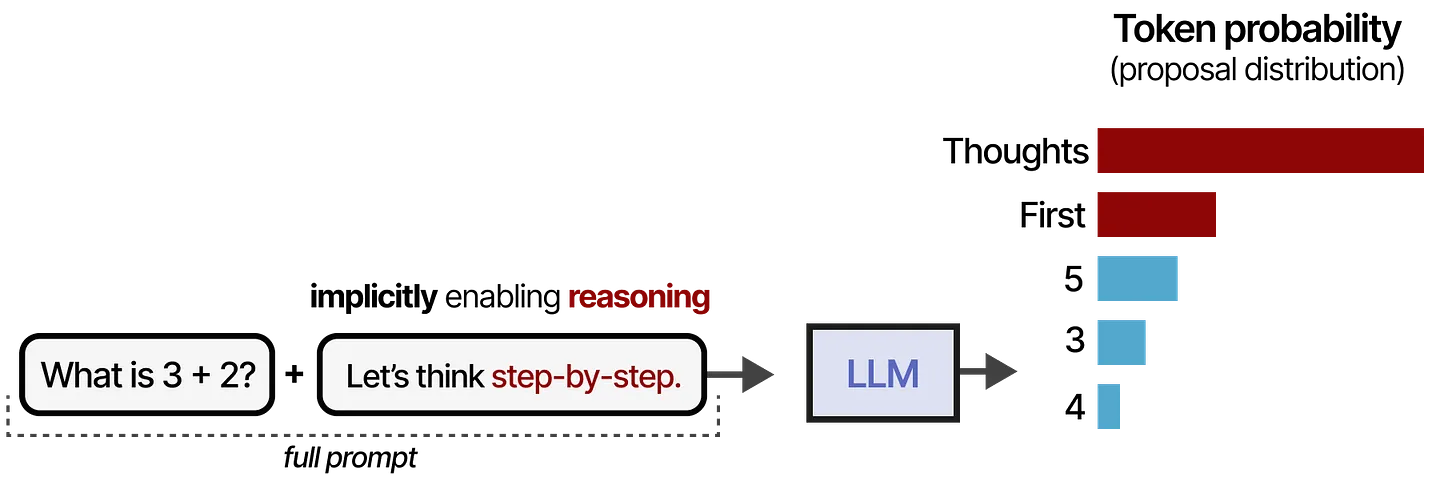
- 图示内容:这里将提示换成 “Let’s think step-by-step”,问题仍然是 “What is 3 + 2?”。
- 模型产生更显式的推理过程(用红色块示意),再输出正确答案 5。
- 整个思路类似图1,但更加突出“分步骤思考”对最终答案生成的影响。
然而,这并不意味着模型本身已经内化了这种推理能力——它并没有从根本上学会去“反思”或“修正”错误。如果模型一开始的推理过程是错误的,那么在这种静态且线性的流程中,它往往会一直延续这个错误,而不是对自身推理进行修正。
STaR(Self-Taught Reasoner)
除了通过 prompting(提示)让模型临时展示推理步骤,我们还可以让模型在训练中因为“产生正确推理步骤”而得到奖励,从而让它真正“学会”推理。这通常需要在大量带有推理过程的数据上进行训练,并结合 reinforcement learning(强化学习)来奖励特定的行为。
一个颇受争议(“much-debated”)的技术就是 STaR,即 Self-Taught Reasoner。它是让 LLM 生成自己的推理数据,再把这些数据用于对模型进行精调(fine-tuning)的过程。
1. STaR 的流程概述
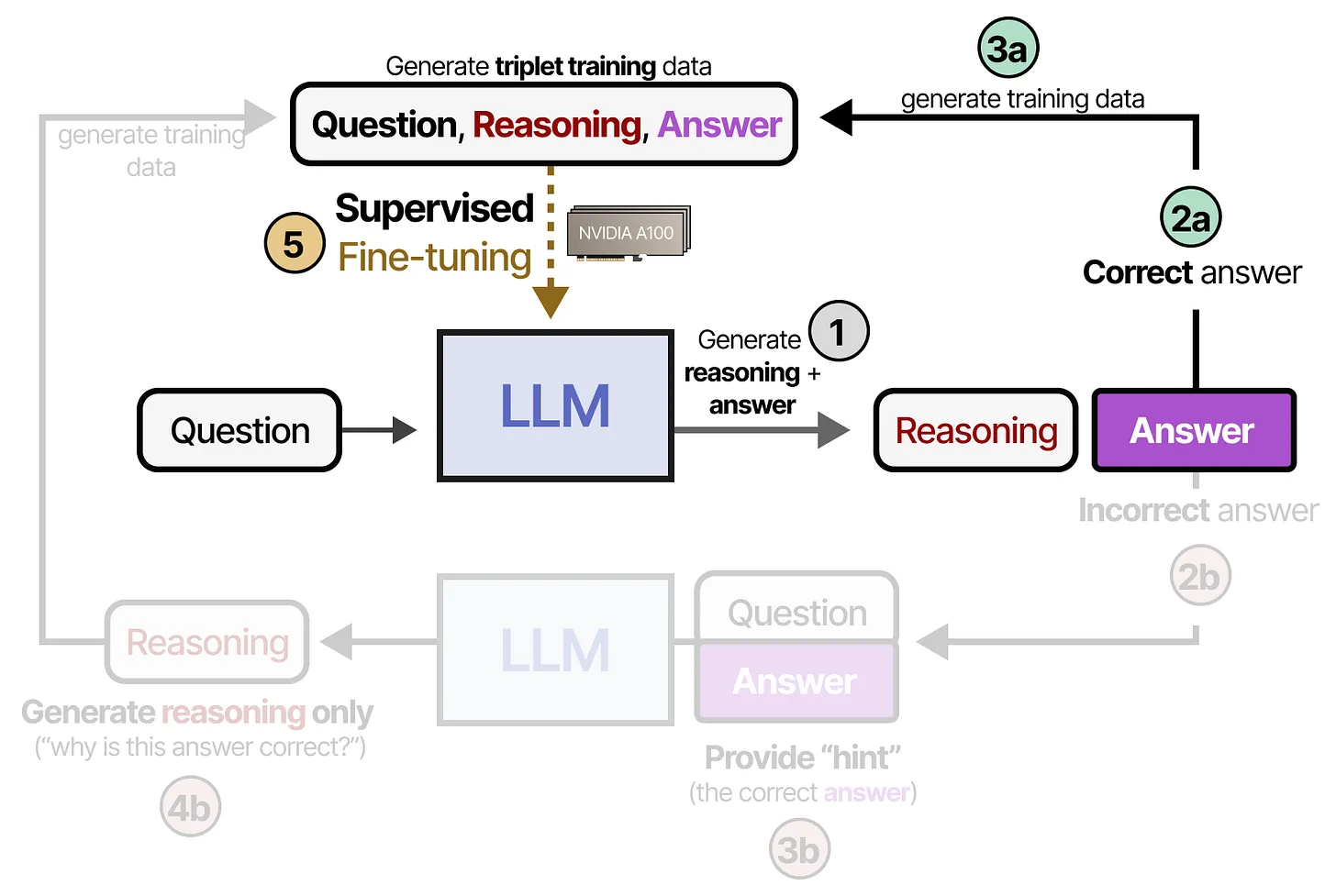
- 这幅图概括了 STaR 的工作原理:
- Generate reasoning + answer:模型先针对输入问题生成一段 reasoning(推理)和一个 answer(答案);
2a. 如果答案正确(Correct answer),则将 Question, Reasoning, Answer 作为训练样本添加到三元组数据集中(3a);
3b. 利用这些三元组数据进行 supervised fine-tuning(监督微调),让模型学会在类似情形下产出正确推理与答案。
- Generate reasoning + answer:模型先针对输入问题生成一段 reasoning(推理)和一个 answer(答案);
如果模型给出了错误答案,则会触发另一条路径:
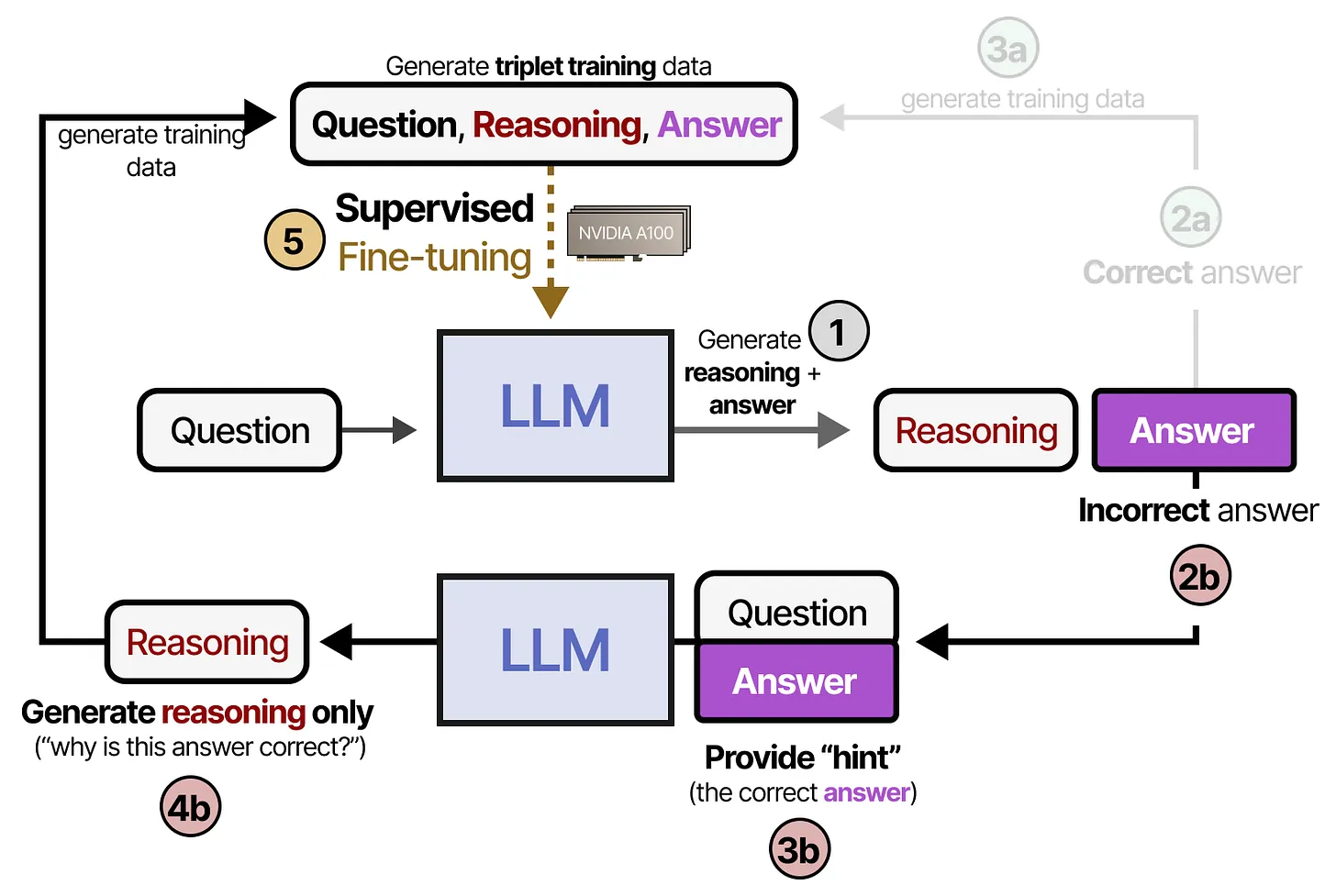
- 当 (2b) 模型答案错误时,我们提供正确答案作为 hint(提示),并让模型去思考“为什么这个答案是正确的”;
- 也就是 Generate reasoning only (why this answer is correct?);
- 得到的这段新的推理依旧会被加入到三元组数据中,然后再进行 supervised fine-tuning。
这里的关键要点是,我们可以通过这种方法显式地训练模型“应该如何进行推理”,而不仅仅是让它临时地模仿推理过程。我们要对模型的推理方式进行监督(supervised fine-tuning),从而把我们想要的推理模式“灌输”给模型。
2. 自动生成合成训练样本
STaR 的整个流程非常有趣,因为它会自动生成合成训练样本(synthetic training examples)。这些样本不仅包含问题和答案,还包含一系列推理步骤,能够帮助模型更好地学习如何“思考”。在其他研究中(例如 DeepSeek R-1),我们可以利用这些合成样本来蒸馏(distill,意为“提炼和保留关键信息”)推理过程到其它模型上。也就是说,一个掌握了推理能力的模型可以帮助另一个模型更快地学会类似的推理。
重点:
- Prompting(提示)能够影响模型的输出风格和思维过程,比如使用 “Let’s think step-by-step” 让模型显式给出推理步骤,但并不保证模型自动纠正错误。
- STaR(Self-Taught Reasoner)等方法则通过生成推理数据、监督微调和奖励机制,帮助模型真正学会按照指定的推理方式去思考和回答问题。
- 无论是哪一种方法,都可以视为对 proposal distribution 的调节:要么是提示时临时nudge(引导),要么是从训练根源上进行调教,让模型内化这种推理过程。
- 利用 in-context learning 提供示例,能够让模型模仿推理风格。
- 用 reinforcement learning 或监督微调(supervised fine-tuning)可以使模型逐渐掌握我们期望的推理模式。
- STaR 方法会自动收集“正确推理”数据并进行训练,使得模型在后续回答中更可能产生正确且符合要求的推理步骤。
DeepSeek-R1
1. 简介
DeepSeek-R1 是一个在推理(reasoning)模型领域的重大版本,其权重已经开源。它直接与 OpenAI 的 o1 推理模型展开竞争,并在这一领域产生了重大影响。
DeepSeek 项目在将推理功能优雅地整合进其基础模型(DeepSeek-V3-Base)方面成就卓著,采用了多种技术来完成这一目标。
有趣的是,该项目在训练过程中并未依赖额外的验证器(verifier),而且并不是单纯地依靠监督微调(supervised fine-tuning)来提炼推理行为。相反,强化学习(Reinforcement Learning, RL) 在其中扮演了重要角色。
以下我们将一起探究他们是如何在模型中训练出推理行为的!
2. DeepSeek-R1 Zero:推理的关键探索
在通往 DeepSeek-R1 的道路上,有一个名为 DeepSeek-R1 Zero 的实验性模型为这次突破打下了基础。它从 DeepSeek-V3-Base 出发,完全不使用大规模监督微调来加入推理数据,而是只依靠 强化学习 来获得推理能力。
训练过程与系统提示(Prompt)
在此过程中,他们首先准备了一个非常直接的提示(prompt),其形式类似于系统提示(system prompt),用来作为推理管线的一部分。下文即展示了相关提示。请注意,其中明确指出了推理过程要写在 <think> 标签内、答案要写在 <answer> 标签内,但没有进一步规定推理过程应如何具体呈现或组织。

在上图中,可以看到一个简化版的对话示例(System prompt 与 User prompt)以及模型如何将推理(reasoning)放在 <think> 标签内、将答案(answer)放在 <answer> 标签内。该图突出展示了在提示(prompt)中对模型的约束:
- “The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.”
- 要求使用
<think>进行推理,使用<answer>进行回答。
这里并未提供关于“推理过程”格式的其他例子或模板——完全由模型自己在训练中摸索出要如何输出“Chain-of-Thought”式的推理文字。
强化学习奖励
在训练中,采用了两个基于规则(rule-based)的奖励机制:
- 准确性奖励(Accuracy rewards)
通过测试给出的答案是否正确来进行奖励。若模型输出的答案正确,就会增加奖励。 - 格式奖励(Format rewards)
奖励模型对<think>和<answer>标签的正确使用。
他们所使用的强化学习算法名为 Group Relative Policy Optimization(GRPO)。此算法的直观想法在于:使所有导致正确或错误答案的决策更易或更难再次出现。这些决策可能包括模型生成的某些标记(token)序列,也可能包括推理步骤本身(即思考过程)。下文给出了这一训练阶段的示意图。
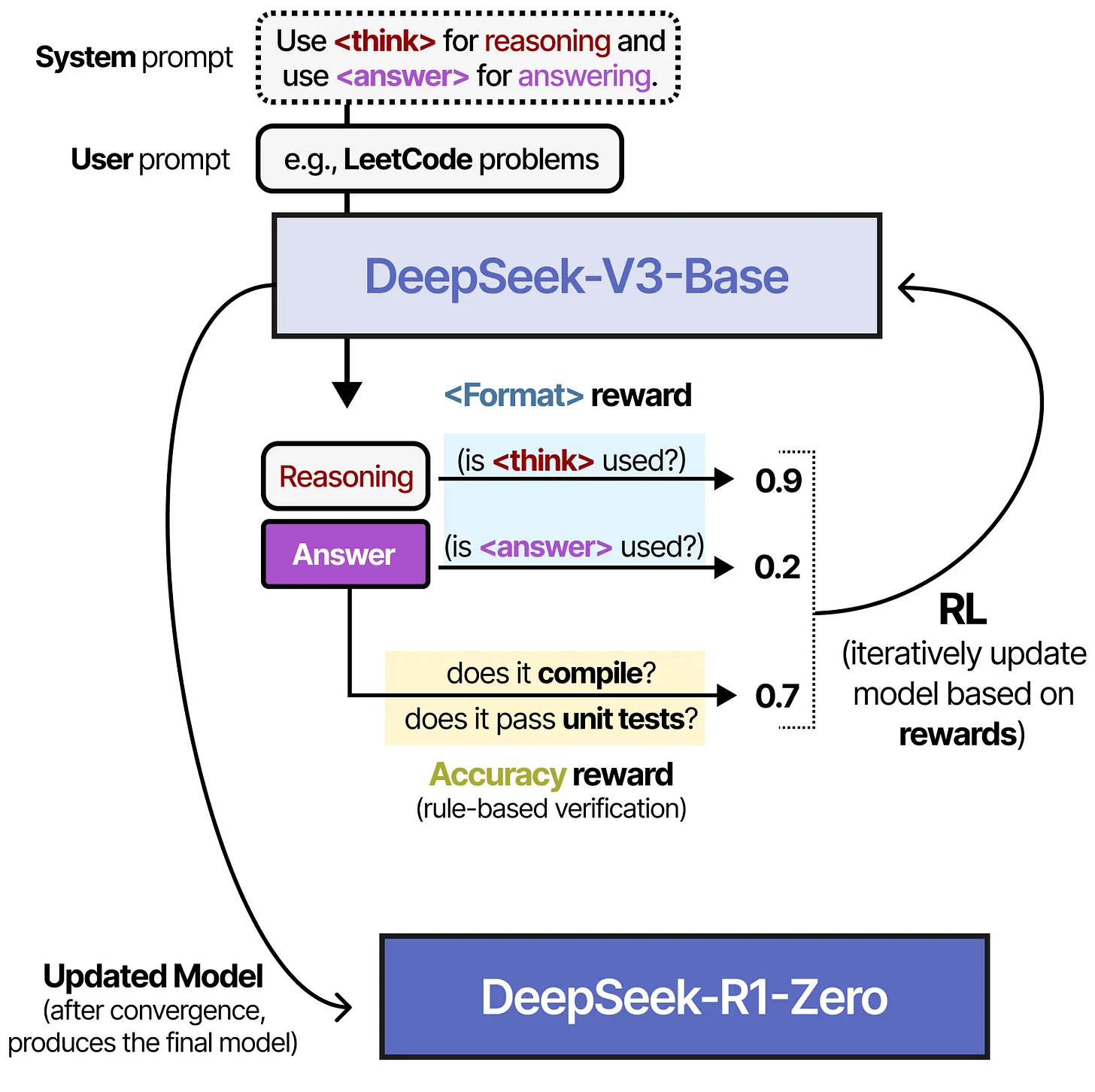
在图中,重点展示了在 RL(强化学习)过程中所使用的两类奖励:
- “is
<think>used?” —— 为使用<think>标签而打分。 - “is
<answer>used?” —— 为使用<answer>标签而打分。
除此之外,还有对答案正确性的奖励(accuracy reward)。图中箭头所示的循环代表了在训练中不断迭代更新模型,使之越来越倾向于正确的推理方式并合乎格式要求。
自发推理行为的出现
值得一提的是,研究人员并没有向模型提供任何示例来告诉它 <think> 标签中的内容应该如何书写或展开。他们仅仅告诉模型:
“It should use
<think>tags, and nothing more!”
通过对“Chain-of-Thought”相关行为进行间接奖励(即只要推理正确、使用正确格式,就鼓励输出更完整的推理内容),模型在训练中自发地学会了越写越长的推理过程,也更易产生正确答案。
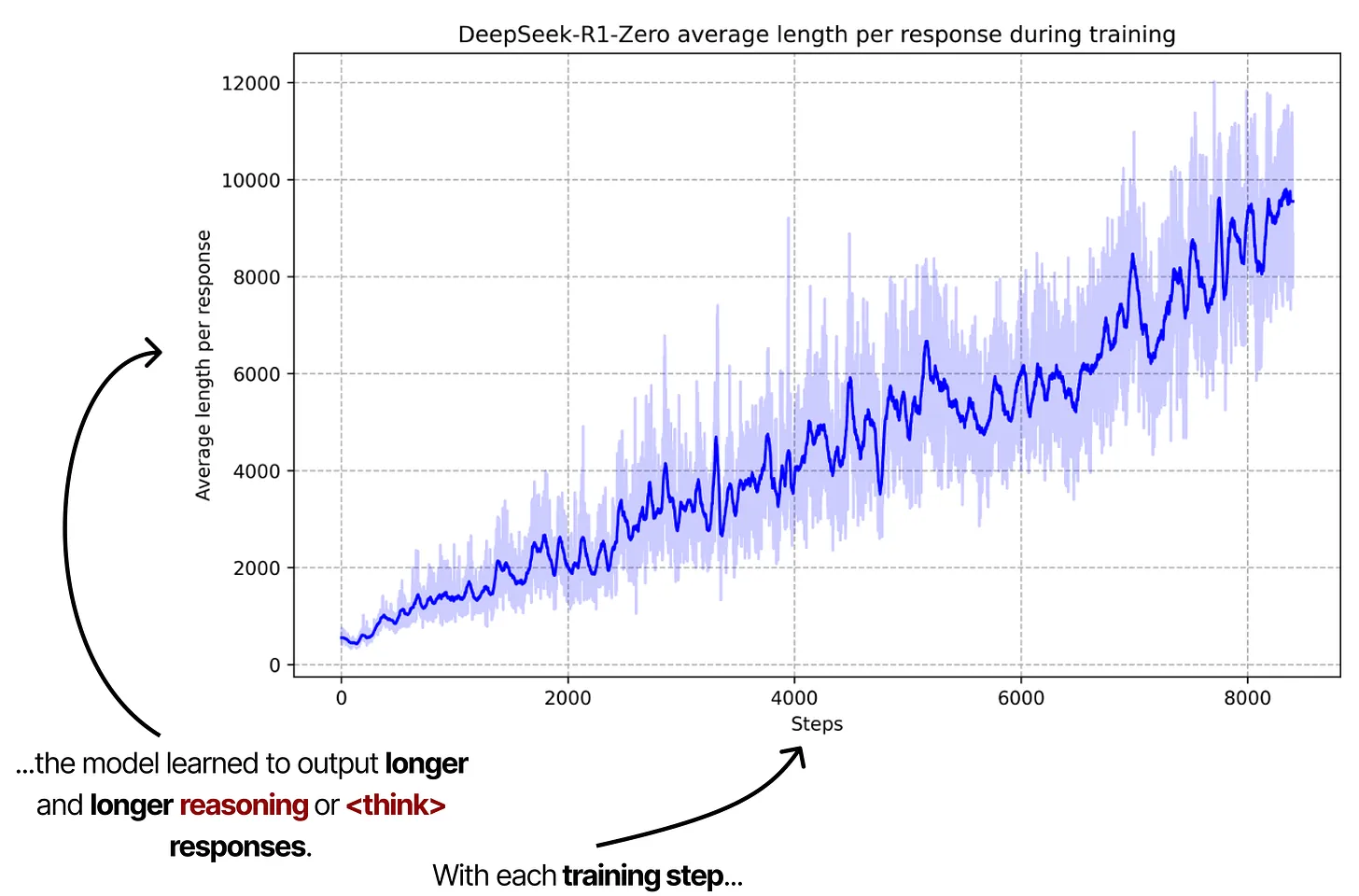
上图呈现了模型在训练过程中输出的推理长度随训练步数增加而逐渐变长的趋势。纵轴是每个响应的平均长度,横轴是训练步数。可以看到,曲线整体是向上攀升的,这表明模型不断倾向于输出更长、更详细的思考内容(Chain-of-Thought),并因此获得更高奖励。这种做法将大部分计算消耗从训练阶段(train-time compute)转移到了推理阶段(test-time compute),也就是在推理时才生成更长的思考过程。
根据研究,他们发现通过这种训练策略,模型能够自行发现最优的 Chain-of-Thought 风格的思考方式,并展现出高级的推理能力,例如:自我反思(self-reflection) 和 自我验证(self-verification)。
不过,DeepSeek-R1 Zero 的模型输出仍存在一些问题,比如可读性欠佳,且有时会混用多种语言。为了在产品化或发布级别进一步完善,研究人员提出了另一个选项,也就是在正式版本中使用的 DeepSeek R1。
3. 深入了解 DeepSeek-R1
要构建 DeepSeek-R1,作者共进行了以下五个关键步骤:
- 冷启动(Cold Start)
- 以推理为导向的强化学习(Reasoning-oriented Reinforcement Learning)
- 拒绝采样(Rejection Sampling)
- 监督微调(Supervised Fine-Tuning)
- 在所有场景下进行强化学习(Reinforcement Learning for all Scenarios)
接下来我们依次展开说明。
第一步:冷启动
在第一步中,研究人员先使用了一个约 5000 个tokens的高质量推理数据集对 DeepSeek-V3-Base 进行微调,以避免产生可读性不佳的冷启动问题(cold start problem)。这个微调步骤可以让模型的输出更加可读,不至于在一开始就产生混乱的推理文本。下文展示了这一过程的示意图。
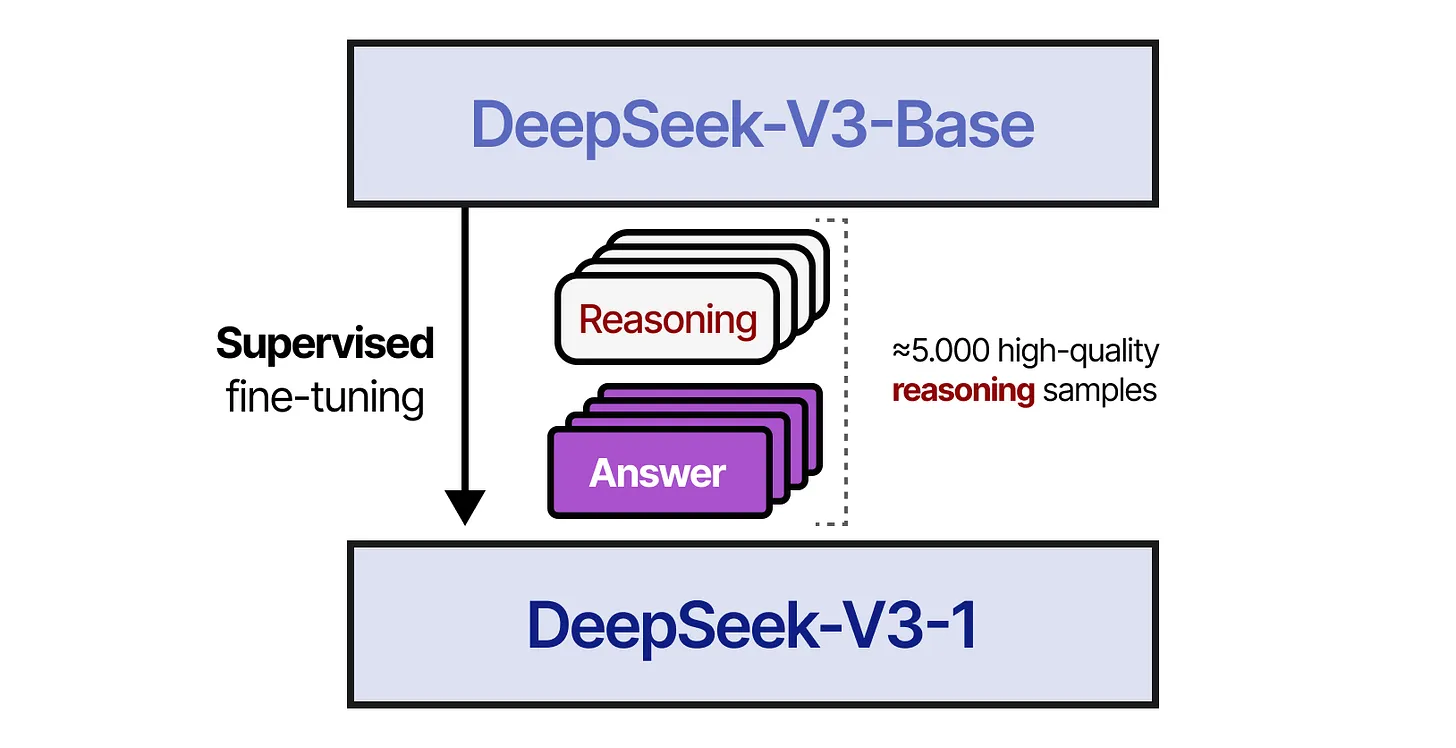
在图中可以看到:
- “DeepSeek-V3-Base” 通过监督微调(Supervised Fine-Tuning)的方式,引入了约 5000 条高质量推理样本。
- 这些样本包含了Reasoning(推理)和Answer(答案)两种部分。
- 该步骤目的是“防止冷启动”,即让模型在一开始就掌握基础的可读性推理。
第二步:推理导向的强化学习
在得到一个初步微调后的模型后(上一步的成果),作者使用与 DeepSeek-V3-Zero 类似的强化学习流程对模型进行训练,但额外加入了目标语言一致性的奖励,以确保模型在推理和回答时不会混用多种语言。
除了之前提到的准确性(accuracy reward)和格式(format reward)等,还增加了语言奖励(language reward)来保证生成的语言风格或语言类型保持一致,不至于出现“中英文混杂”或“风格不稳”的现象。
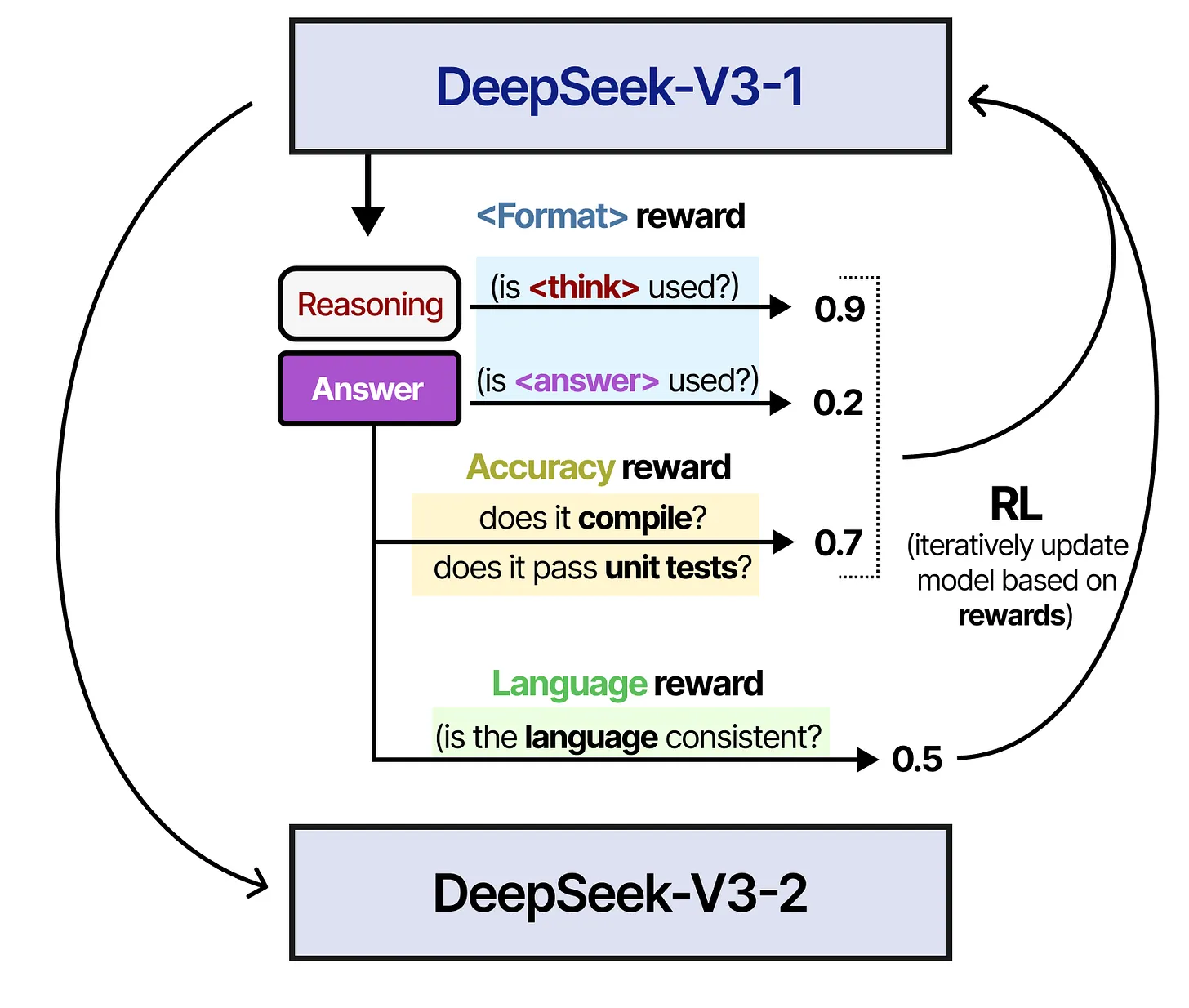
- Format reward:依旧关注
<think>和<answer>的使用。 - Accuracy reward:检查答案是否正确,以及是否能通过相应的“单元测试”。
- Language reward:检查语言是否一致、通顺以及是否符合目标语言要求。
这些奖励综合起来,通过强化学习(RL)循环使模型的推理和答案在可读性、准确度和语言风格方面逐渐优化。
第三步:拒绝采样
在这一阶段,作者用第 2 步强化学习后得到的模型,来大规模生成合成推理数据,并配合 DeepSeek-V3-Base 模型来进行“评估”和“规则过滤”,最终产生约 60 万条高质量的推理样本可用于后续监督微调。同时,他们还另外生成了约 20 万条非推理样本,包含了写作、简单问答、自我认知、翻译等多种任务数据。下文总结了这一过程。
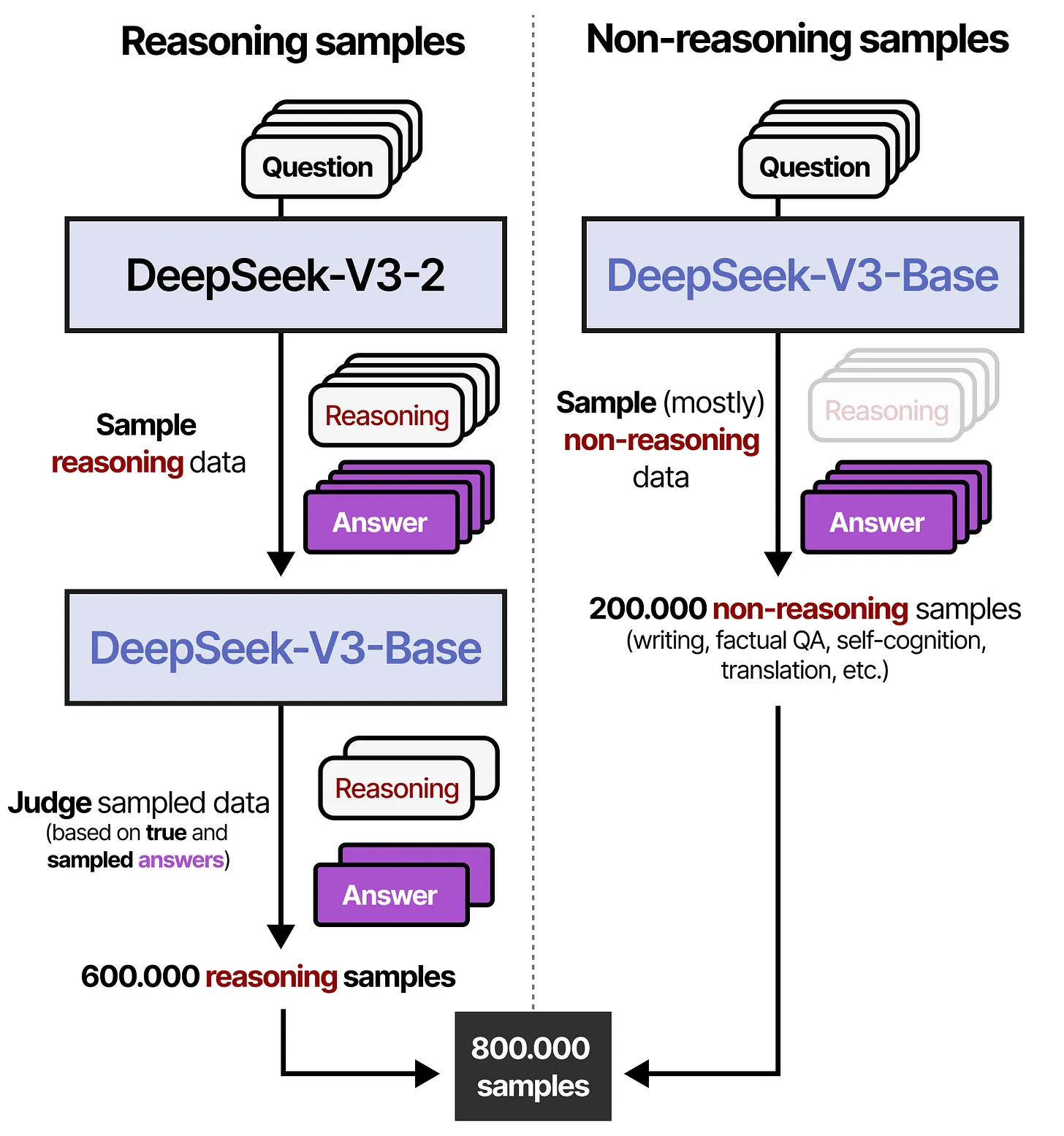
- 左边展示了DeepSeek-V3-2 如何采样到大量Reasoning(推理)和Answer(答案),再利用基于规则的筛选和 DeepSeek-V3-Base 的判断(判断生成的内容质量),保留质量更好的推理数据(约 600,000 条)。
- 右边展示了非推理(non-reasoning)数据采样流程,来自 DeepSeek-V3-Base 所使用的一部分数据,总共约 200,000 条,这些数据主要涉及写作、事实性问答(factual QA)、自我认知、翻译等方面。
由此,研究人员得到规模约 80 万条的“混合”数据,其中既有推理样本,也有非推理样本。
第四步:监督微调
在得到上述 80 万条数据后,研究人员再次对 DeepSeek-V3-Base 进行监督微调,具体过程如下图所示。
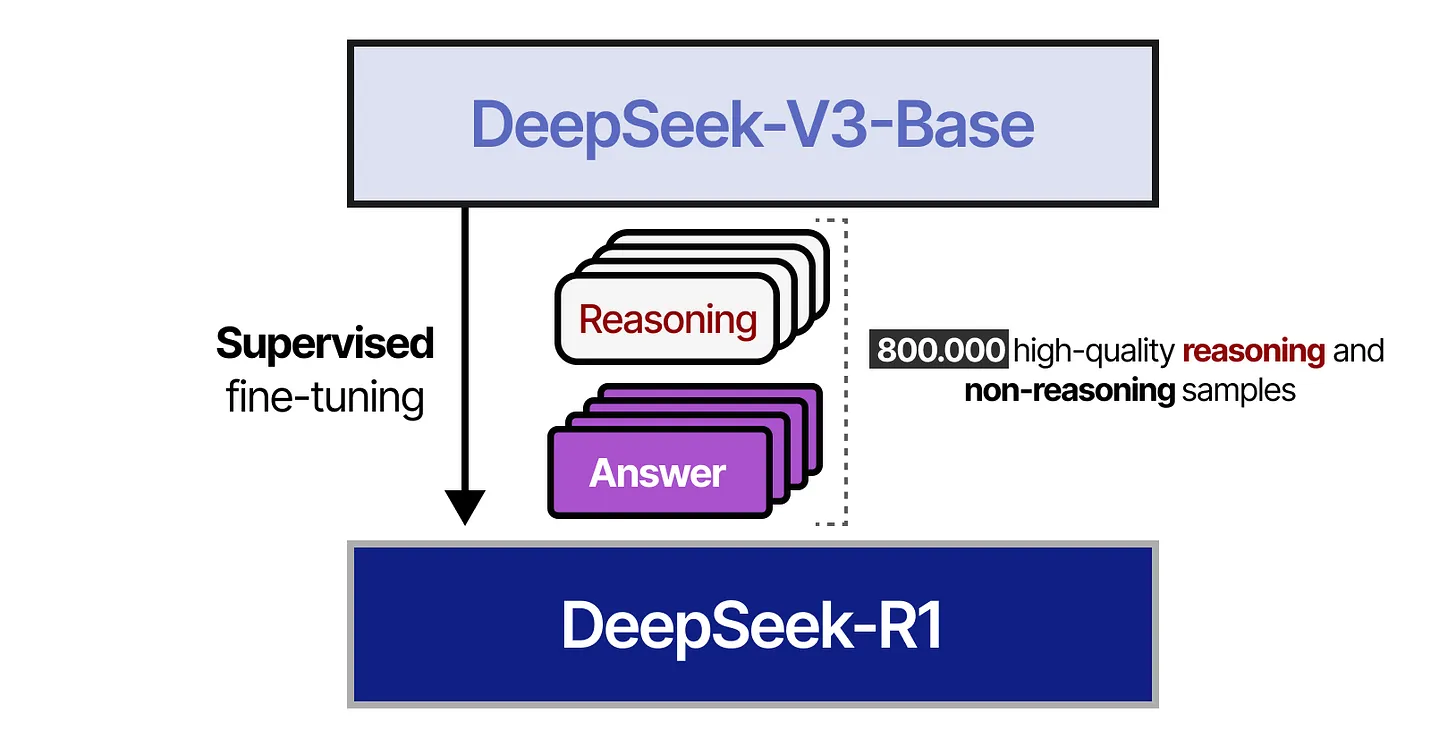
- 在图中,我们看到“DeepSeek-V3-Base”被用于执行监督微调(Supervised Fine-Tuning),使用的正是前文所提到的 800,000 条高质量推理与非推理样本。
- 这一阶段使得模型在更大规模的数据基础上,学习到更广泛、更多样的推理形式和任务形式。
第五步:在所有场景下的强化学习
在监督微调完成后,研究人员继续采用类似 DeepSeek-R1-Zero 的方法进行 RL(强化学习) 训练。但是,为了让模型更符合人类偏好,他们在这个阶段引入了更多的 “有益与无害”(helpfulness and harmlessness) 奖励信号,用来约束模型的回答。
同时,模型也被要求对推理过程进行总结(summarize),以防止在最终输出时显示出过长、难以阅读的推理文本。这一步骤解决了前述提到的可读性问题。
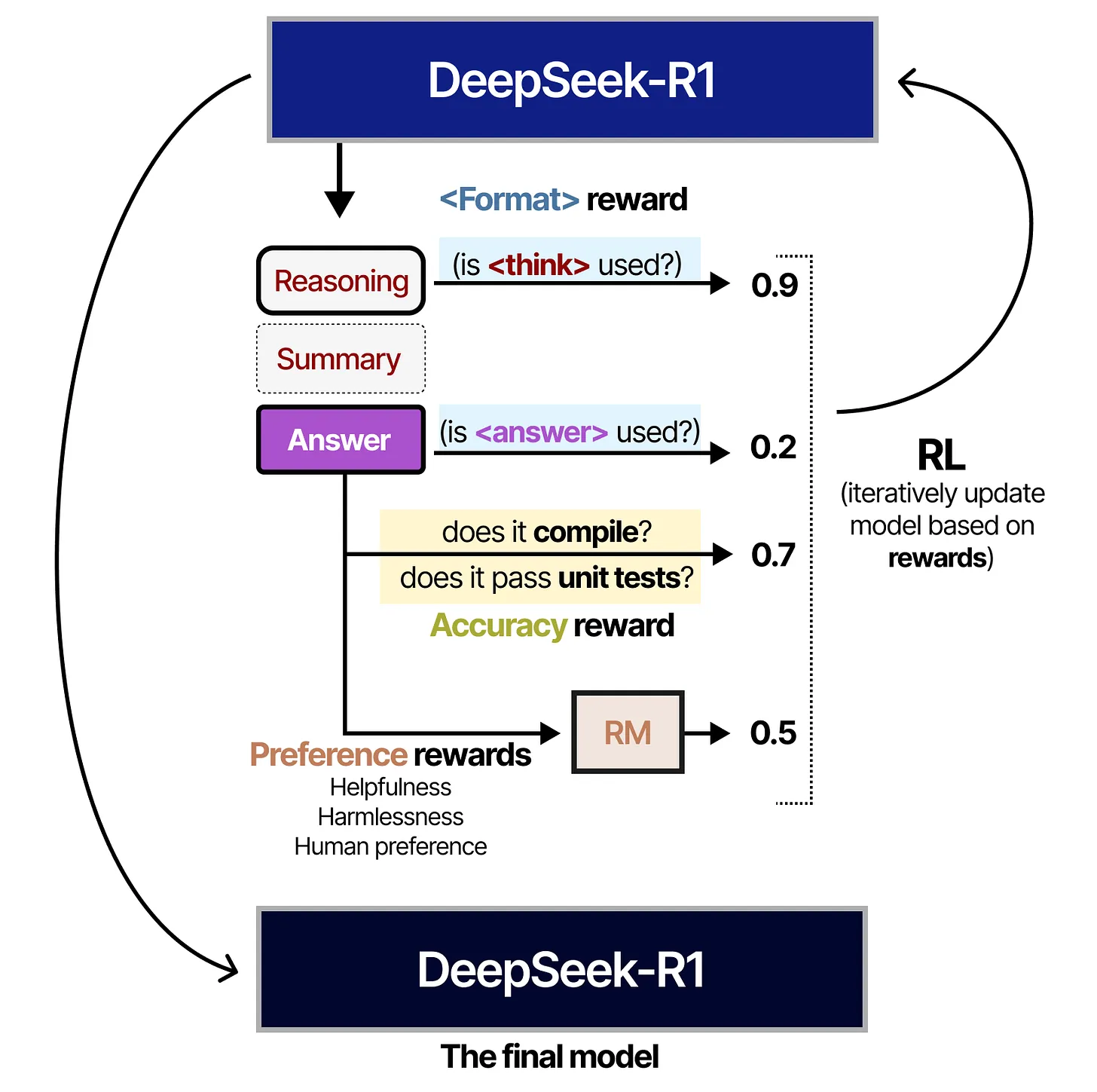
- Format reward(格式奖励)
- 是否正确使用
<think>标签书写推理内容 - 是否正确使用
<answer>标签输出答案
- 是否正确使用
- Accuracy reward(准确性奖励)
- 测试输出是否能编译(“does it compile?”)
- 是否能通过单元测试(“does it pass unit tests?”)
- Preference rewards(偏好奖励)
- 关注 Helpfulness(有益)、Harmlessness(无害)、Human preference(人类偏好) 等
- 由 RM(Reward Model) 模块来评估这些偏好指标
图中可以看到,Reasoning(推理)阶段和 Answer(答案)阶段需要分别用 <think> 和 <answer> 标签进行明确区分。同时,为了输出更为精简、可读的内容,模型也可能产生一个 Summary(总结)片段。强化学习的迭代过程会同时考虑多种奖励信号,从而不断更新模型并得到最终版本的 DeepSeek-R1。
上图中,“RM” 即 Reward Model,用于对偏好进行打分(如对话是否友善、是否符合伦理要求等),再把结果反馈给模型。
“And that’s it!”这意味着 DeepSeek-R1 实际上是 DeepSeek-V3-Base 经过监督微调(Supervised Fine-Tuning)和强化学习(RL)进一步优化而成。大量的工作都用于保证高质量数据的生成与使用,进而训练出这样一个具备强大推理能力的模型。
将推理知识从 DeepSeek-R1 蒸馏到其他模型
DeepSeek-R1 拥有 6710 亿(671B) 参数。这一规模的模型在普通消费级硬件上运行存在较大难度。出于实用性考虑,作者们研究了如何将 DeepSeek-R1 的推理能力“蒸馏(distill)”到更小的模型(如 Qwen-32B)上,以便能在消费级硬件上部署和使用。
蒸馏过程:Teacher-Student 框架
在蒸馏过程中,DeepSeek-R1 作为教师模型(Teacher),而规模更小的模型(如 Qwen-32B)作为学生模型(Student)。二者面对相同的提示(prompt)时,分别会输出一组词元概率分布(token probability distribution)。训练时,学生模型会尽量学习并接近教师模型的输出分布。
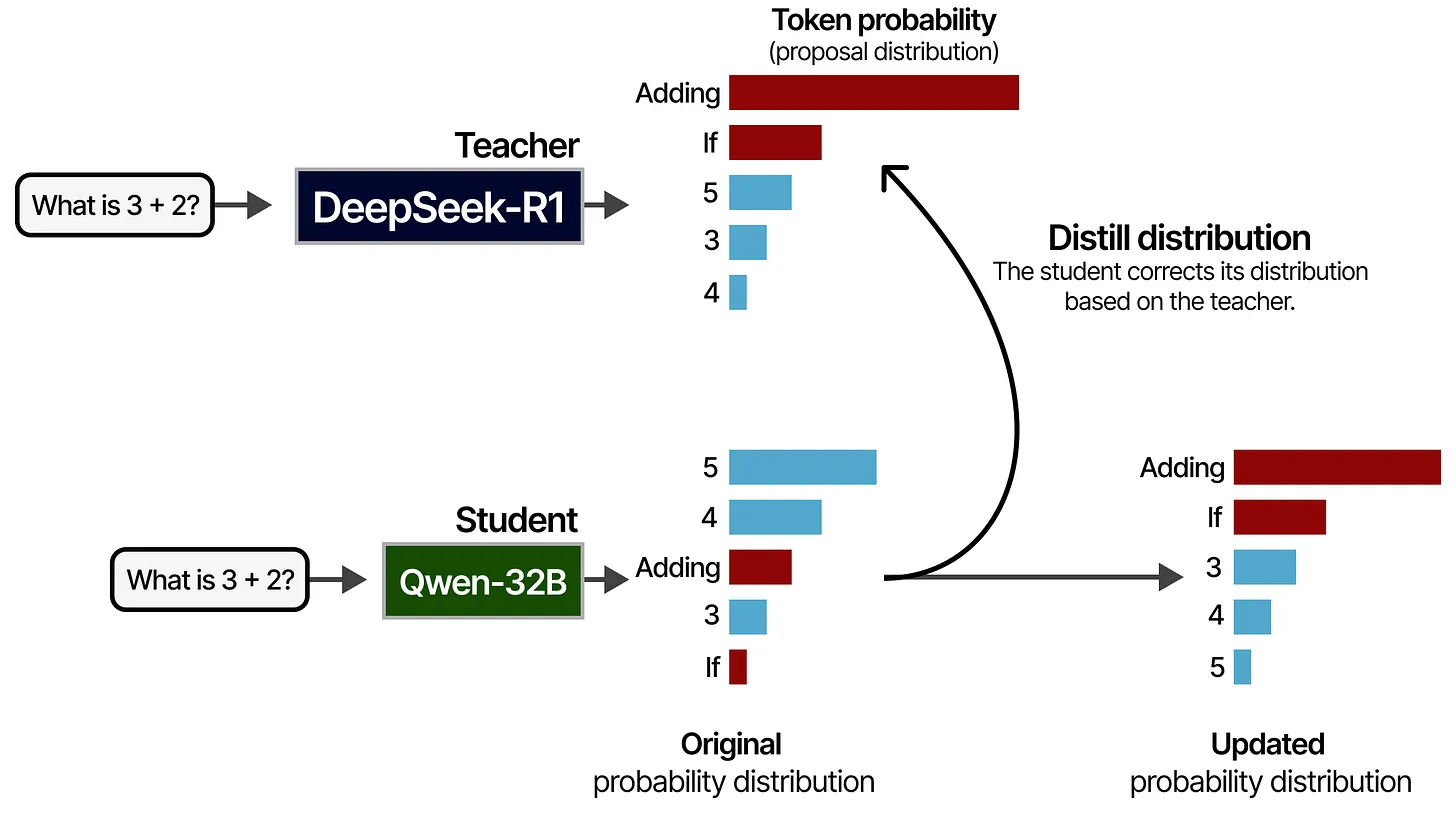
- 教师(DeepSeek-R1)给出自己的“proposal distribution”。例如在回答“What is 3 + 2?”时,教师模型可能倾向输出“Adding”“If”“5”“3”“4”等标记,并赋予各自不同的概率。
- 学生(Qwen-32B)则会在训练中不断更新自己的概率分布,使之更接近教师的分布。
额外解释:
- 概率分布(proposal distribution):语言模型在生成下一个词元(token)时,会输出对所有可能词元的概率估计。
- 蒸馏(distillation):通过比较教师和学生的分布差异,学生会逐步调整自身参数,使其输出更接近教师模型的风格和推理倾向。
训练所使用的数据,正是之前提到的那 80 万条高质量样本——其中包含约 60 万推理样本和 20 万非推理样本。下图展示了这一数据流向:
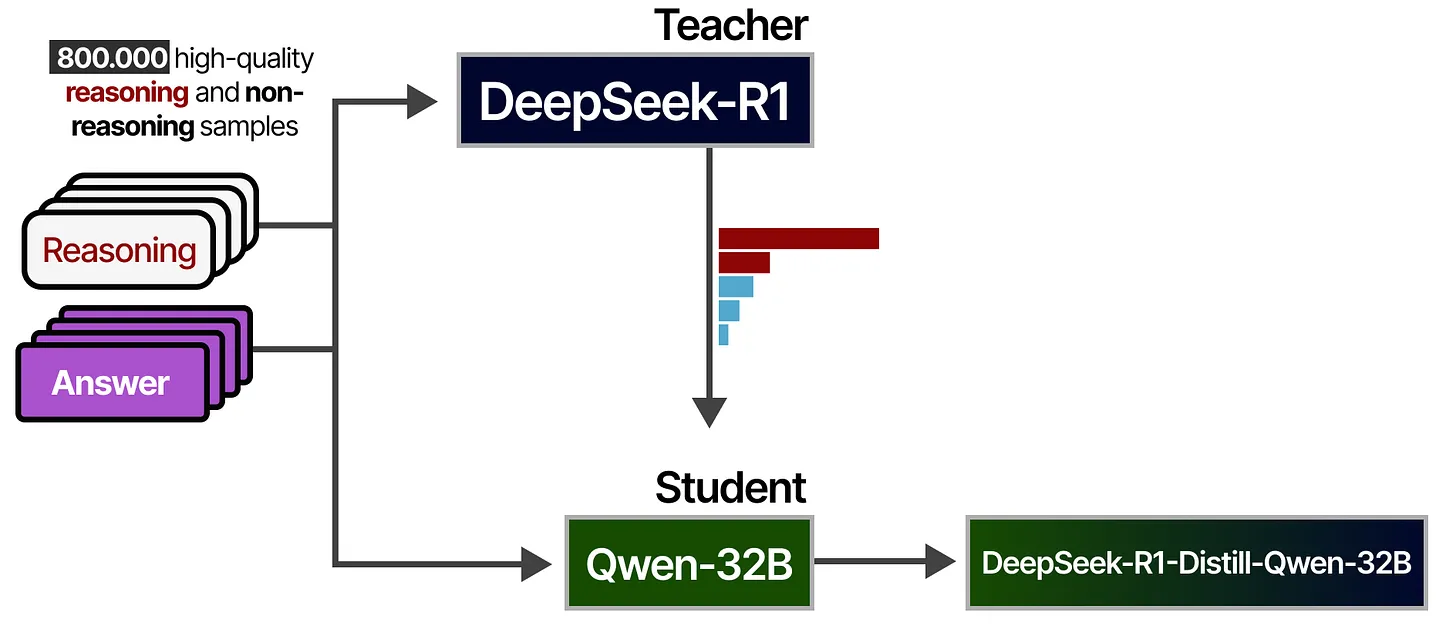
- 左侧的 Reasoning(推理)和 Answer(答案)数据,合计 80 万条。
- 由 DeepSeek-R1(Teacher)生成或评估,得到对应的概率分布。
- 学生模型 Qwen-32B 则根据教师的分布进行学习,最终得到一个蒸馏版本 DeepSeek-R1-Distill-Qwen-32B。

额外解释:
- 学生模型不仅仅学习了那 80 万条样本本身的输入-输出模式,也学习到 DeepSeek-R1 在面对这些数据时所“倾向”采用的推理策略和概率分布,从而在更小模型上复现类似的推理能力。
- “Distilled” 模型往往会在推理质量与计算资源之间找到更好的平衡:虽然可能在性能上略逊色于老师模型,但依然能在大多数常见任务上达到令人满意的结果,并且所需资源更低。
其他未成功的尝试
在研究过程中,DeepSeek 团队也曾尝试过 Process Reward Models(PRMs) 和 Monte Carlo Tree Search(MCTS) 等方法来注入推理能力,但结果并不理想:
使用 MCTS
- 面临的主要问题是搜索空间过于庞大,只能对节点展开进行严格限制。这样一来,效果就大打折扣。
- 此外,精细化训练 Reward Model 也相当困难。
使用 PRMs 进行 Best-of-N 策略
- 如果不断重训练 Reward Model 以防止模型出现“投机取巧”(reward hacking)行为,会带来高昂的计算开销。
这些结果并不意味着这些技术无效,而是说明它们在当前大规模语言模型上的实践还有诸多限制与难点。DeepSeek-R1 之所以取得成功,更多依赖于强化学习 + 监督微调的组合,以及对大规模高质量数据的挖掘与利用。
总结与展望
至此,我们已经大致回顾了 DeepSeek-R1 的推理训练之旅。希望以上内容能够让你更好地理解:
- Test-time compute(推理时计算) 可以通过模型输出更长、更精细的思考过程(Chain-of-Thought)来取得更佳效果。
- 大规模“先监督微调,再强化学习”的训练流程,以及蒸馏到更小模型的技术路线,也展现了在硬件资源和推理性能间取得平衡的方法。
如前所述,DeepSeek-R1 引入了多种奖励机制,尤其是针对格式和人类偏好的奖励,来保证回答既正确又易读。“总结推理过程”(Summary)的做法也在很大程度上改善了纯文本Chain-of-Thought过长而导致的可读性问题。
更多资源
如果你对 Large Language Models(LLMs) 中的推理话题感兴趣,以下资源值得参考:
- The Illustrated DeepSeek-R1
- Jay Alammar 制作的高质量可视化指南,详细介绍了 DeepSeek-R1 模型背后的原理与实现细节。
- Hugging Face 的一篇博文
- 重点讨论了在推理阶段如何对计算量进行扩展,并给出了有趣的实验。
- 视频 “Speculations on Test-Time Scaling”
- 深入探讨了在推理阶段进行各种计算扩展的常用技术细节。
此外,作者在文中也提到了一本关于大型语言模型的著作,内含更多可视化和实验结果,是想进一步研究推理 LLMs 的朋友可以深入阅读的好资料。
- Official Website of the Book: llm-book.com
- Amazon 购买链接: Hands-On Large Language Models: Understanding, Building, and Optimizing LLMs
- GitHub 代码仓库: handsOnLLM/Hands-On-Large-Language-Models
致谢
感谢你阅读本篇关于 DeepSeek-R1 的介绍文档。通过对所有图片与文字内容的依次解读,以及对每个环节所涉及的关键技术进行了更多解释,我们希望让你对 DeepSeek-R1 的训练流程、蒸馏方法和未成功的尝试都有更加全面的了解。
在未来,随着硬件性能的提升与更成熟的训练技术出现,深度推理与模型蒸馏必将在更多实际应用场景中发挥巨大作用。让我们拭目以待!