Gorilla LLM 大语言模型简介
Gorilla LLM 大语言模型简介
🦍 Gorilla: Large Language Model Connected with Massive APIs
Link: https://gorilla.cs.berkeley.edu/blogs/7_open_functions_v2.html
- Berkeley 功能调用排行榜Berkeley 功能调用排行榜
- 在线体验模型:Gorilla OpenFunctions-v2 网络演示
- 项目详情:GitHub
- 模型(7B 参数)在 HuggingFace 上的页面:gorilla-llm/gorilla-openfunctions-v2
1. 伯克利函数调用排行榜
自 2022 年底以来,大语言模型(LLMs)凭借其执行通用任务的强大能力,成为众人关注的焦点。不仅限于聊天应用,将这些模型应用于开发各类 AI 应用和软件(如 Langchain, Llama Index, AutoGPT, Voyager)已成为一种趋势。GPT, Gemini, Llama, Mistral 等模型通过与外部世界的交互,如函数调用和执行,展现了其巨大潜力。
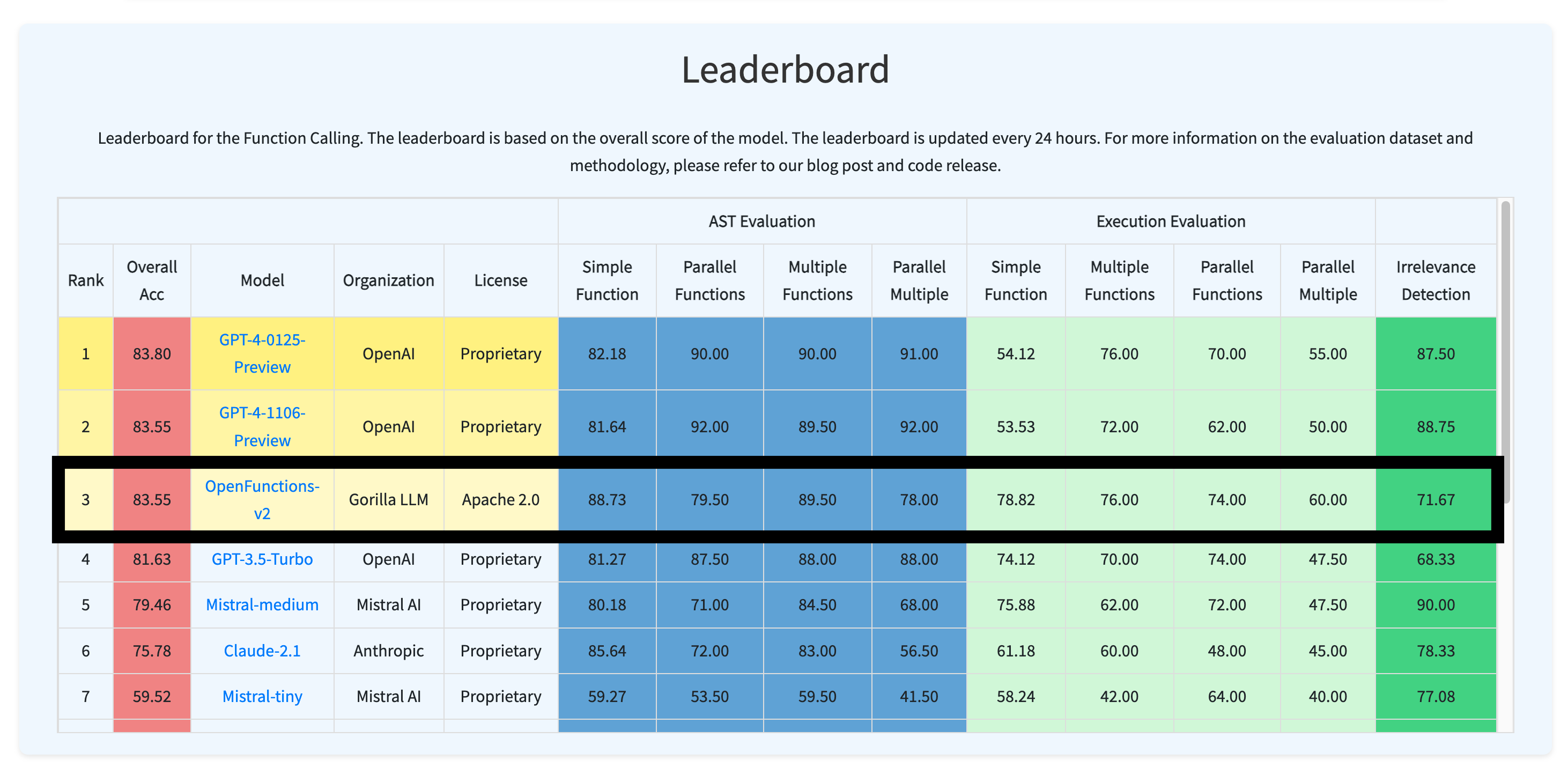
我们推出了伯克利函数调用排行榜(BFCL),这是首个全面且可执行的 LLMs 函数调用评估。与之前的评估如 Anyscale 函数调用数据集不同,我们考虑了更多形式的函数调用、不同场景下的调用,以及函数调用的可执行性。我们根据实际应用场景构建了这个数据集,涵盖了大多数用户可能遇到的函数调用用例,例如在 AI 智能体或企业工作流程中的应用。为此,我们的评估数据集包含了丰富的类别,覆盖了多种语言。同时,我们还发布了 Gorilla-Openfunctions-v2 模型,这是目前最先进的开源模型,能够处理多种编程语言的函数调用,包括并行和多重函数调用。此外,我们还提供了一项特殊的调试功能,即当提供的函数不符合任务要求时,模型会输出“错误消息”。
https://gorilla.cs.berkeley.edu/leaderboard#api-explorer
伯克利函数调用排行榜 🏆
伯克利函数调用
排行榜(BFCL)旨在全面研究不同 LLMs 在函数调用能力上的表现。它包含了 2000 个包含多种编程语言(Python, Java, JavaScript, REST API)的问题-函数-答案对,覆盖了多样化的应用领域和复杂的用例(如多重函数调用和并行函数调用)。我们还研究了函数相关性检测,以确定模型对不适合的函数如何作出反应(在这种情况下会提供“错误消息”)。具体来说,BFCL 包括了 100 个 Java、50 个 JavaScript、70 个 REST API、100 个 SQL 和 1680 个 Python 的各种简单、并行、多重、可执行函数调用场景以及函数相关性检测。
排行榜显示,OpenAI 的 GPT-4 在函数调用评估中仍领先,而 Gorilla OpenFunctions-v2(来自 Gorilla LLM)的表现几乎与之媲美。其后是 Mistral-medium 模型(来自 Mistral AI)和 Claude-2.1(来自 Anthropic)。这说明,一个经过微调的开源模型在函数调用任务上也可以达到与专有模型相近的水平,而无需进行复杂的链接。
我们致力于涵盖真实世界的用例和多样的语言。未来,我们将继续扩展测试领域,并探索更多创新用例。

LLMs 在伯克利函数调用排行榜(BFCL)上的表现
为了更深入地分析和可视化结果,我们提供了一个交互式的六边形工具,供用户比较不同模型的性能。我们将测试分为 9 个类别,包括函数不相关性检测、AST 树检查和执行函数调用检查,用于简单、多重、并行多功能场景。通过这个工具,我们可以清楚地看到各个测试中模型的表现。在简单单一函数调用方面,专有模型和开源模型表现类似。但在涉及多重和并行函数调用时,GPT 系列模型的表现超过了开源模型。
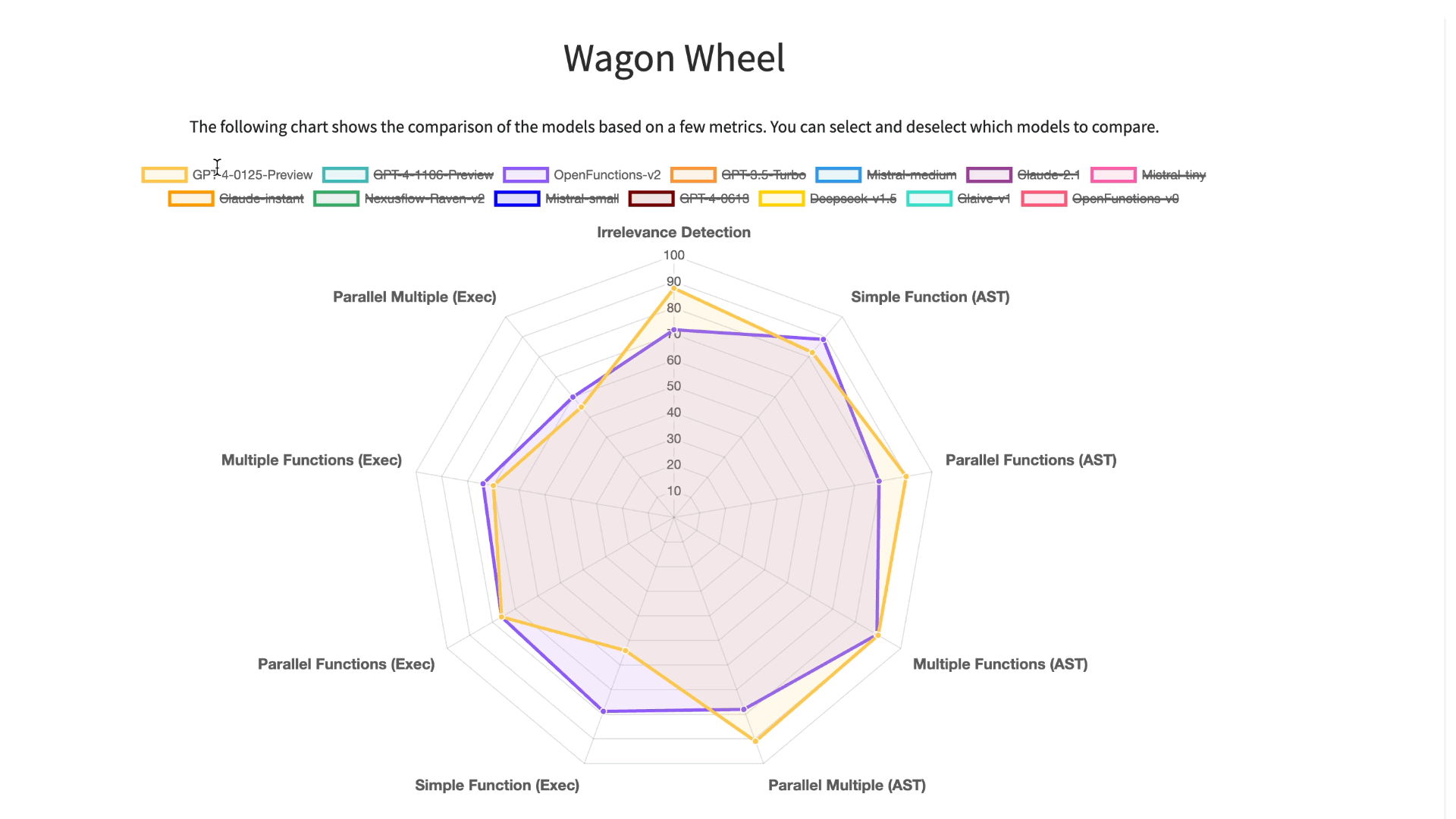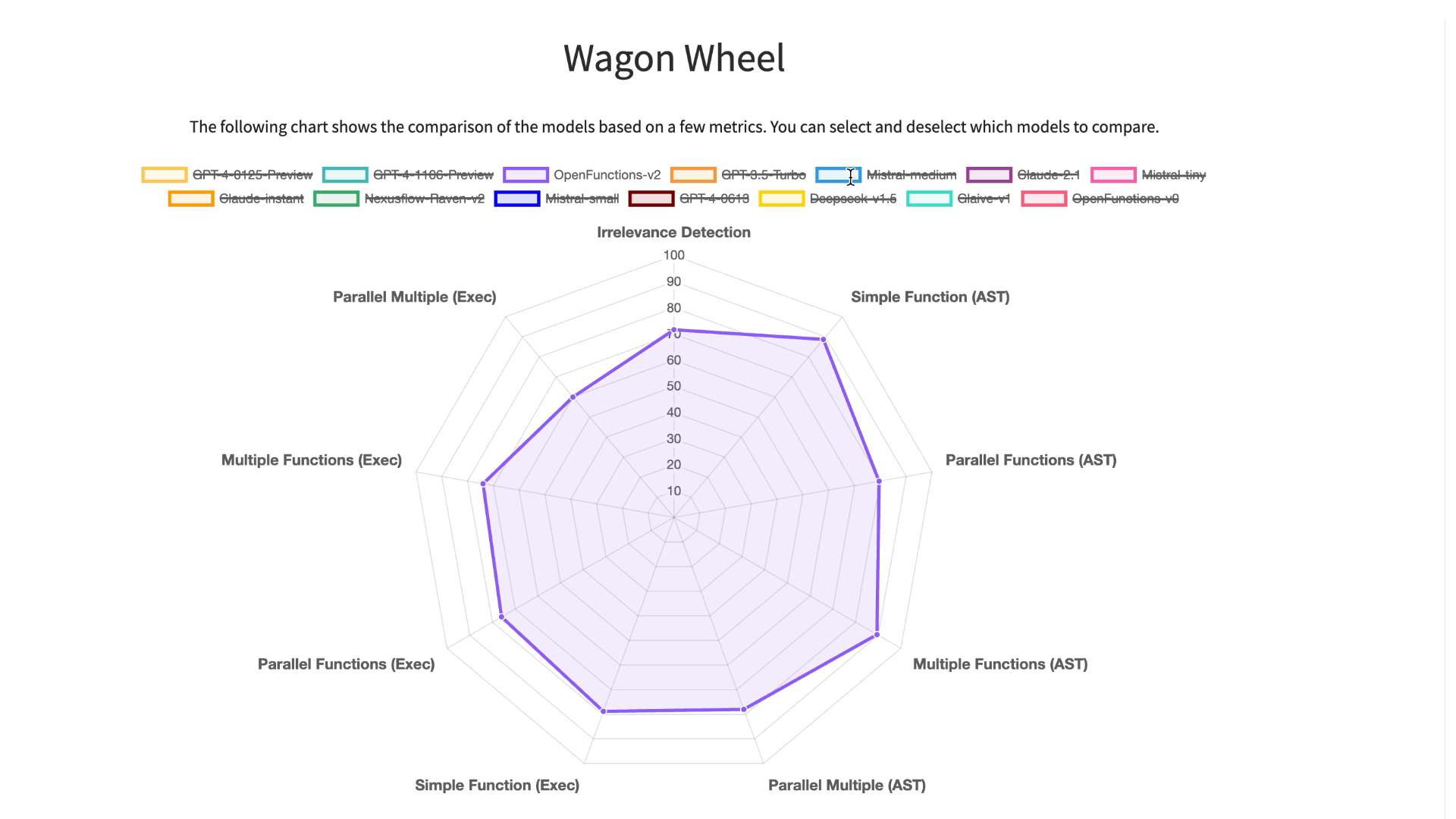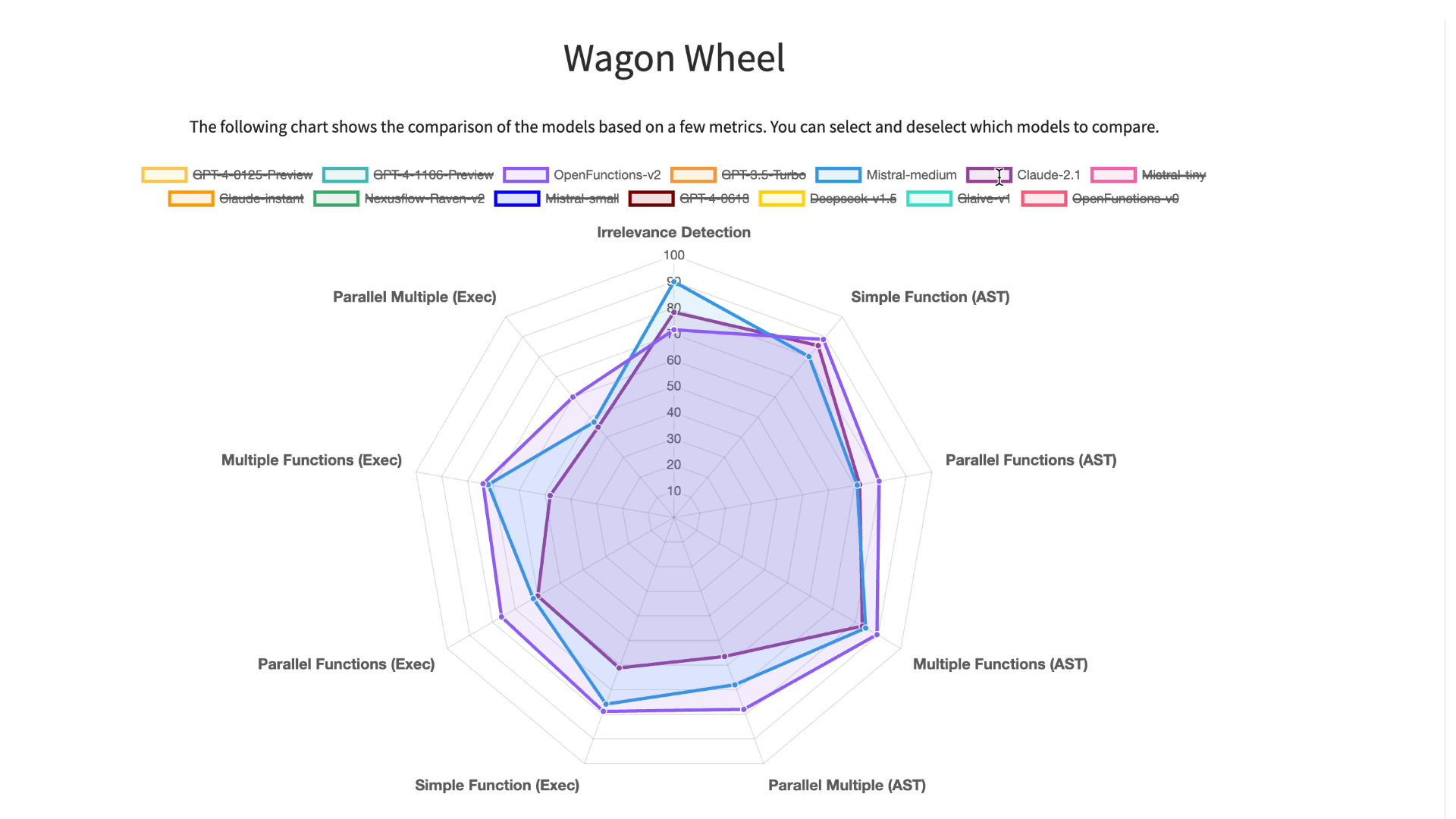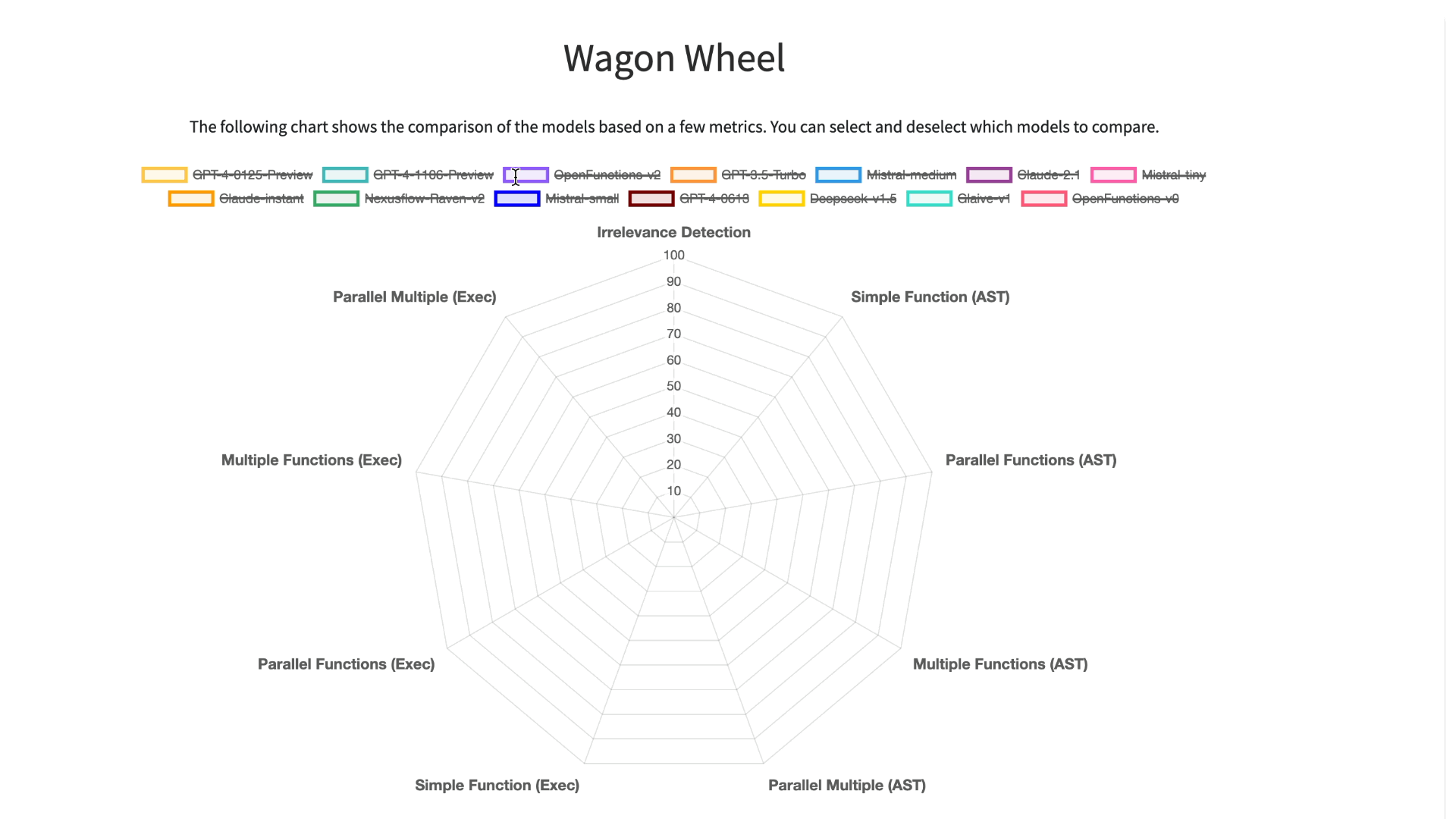
使用伯克利函数调用排行榜(BFCL)六边形图进行的详细分析
数据集组成
Gorilla OpenFunctions 的评估数据集已从最初的 100 个条目扩展到 1900 个。评估数据集在以下方面展现了多样性:
- 函数文档领域
- 函数文档和函数调用问答对的数量
- 不同编程语言的数据类型
我们的评估 JSON 函数是从不同网站来源抓取和生成的。我们特意包含了像数学代数、体育足球、金融抵押等领域。我们在评估中包括了 40 个子领域的函数,这使我们能够了解模型性能在数据丰富的领域(如计算和云)以及体育、法律等小众领域的表现。
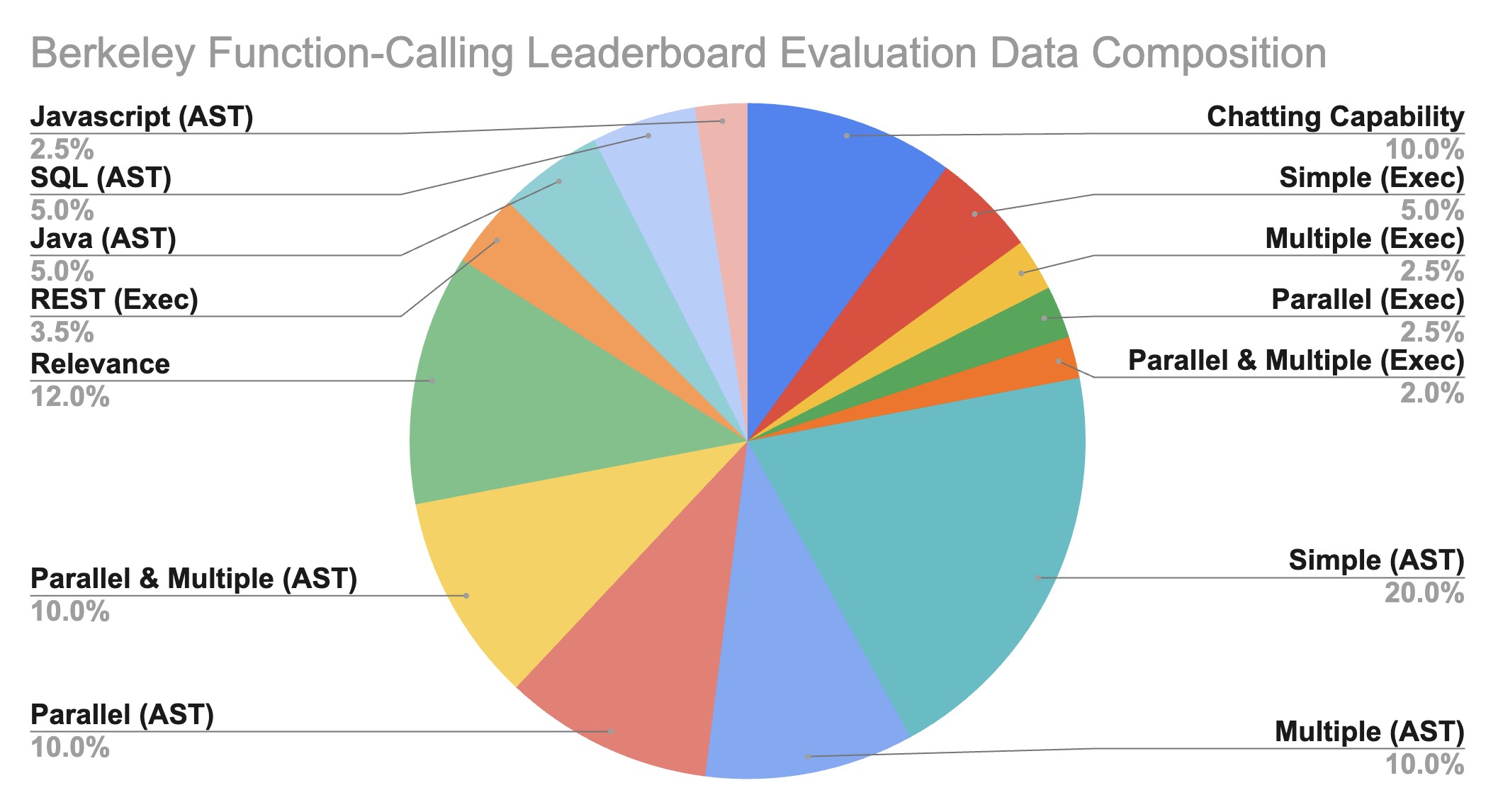
伯克利函数调用排行榜(BFCL)数据组成
评估类别 📊
我们将评估主要分为两大类:
- Python:简单函数、多重函数、并行函数、并行多重函数
- 非 Python:函数相关性检测、REST API、SQL、Java、JavaScript
Python 评估
- 简单函数:这一类别包含了最常见的格式:用户提供一个 JSON 函数文档,模型只调用其中一个函数。
- 多重函数:这一类别包含了需要从 2-4 个 JSON 函数文档中选择并调用一个函数的用户问题。模型需要根据用户提供的上下文选择最合适的函数。
- 并行函数:并行函数定义为使用一个用户查询同时调用多个函数。模型需要判断需要调用多少个函数,问题可以是单个或多个句子。
- 并行多重函数:并行多重函数是并行函数和多重函数的结合,即模型被提供了多个函数文档,每个文档中的函数可能被调用一次或多次。
每个类别都有相应的可执行类别。在这部分,我们根据一些免费的 REST API 端点(例如获取天气)和直接计算的函数(例如线性回归)编写了函数代码。可执行类别旨在判断函数调用生成是否能够在实际应用中使用。
非 Python 评估
除了上述主要类别外,我们还包含了更具体的类别来评估模型在不同场景下的表现,并测试其对不相关问题和函数文档的应对能力。
- 函数相关性检测:这一类别设计了一个场景,其中提供的任何函数都不相关,也不应该被调用。我们期望模型的输出是没有函数调用。这个场景帮助我们了解模型是否会在缺乏生成函数代码的信息时产生错误。
- REST API:现实世界中的大多数 API 调用都是 REST API 调用。Python 主要通过 requests.get(), requests.post(), requests.delete()等方法在 python requests 库中完成 REST API 调用。
- GET 请求:GET 请求是现实世界中最常用的。因此,我们包括了真实世界的 GET 请求来测试模型生成可执行 REST API 调用的能力。我们的评估包括两种变体:一种是需要在 URL 中传递参数的,另一种是需要将参数作为键/值对放入 requests.get()的 params 和/或 headers 中。模型需要根据情况决定如何调用。
- SQL:SQL 评估数据包括我们定制的 sql.execute 函数,其中包含 sql_keyword, table_name, columns 和 conditions。这些参数提供了构建简单 SQL 查询的必要信息。我们希望通过函数调用可靠地构建和使用 SQL 查询,而不是专门训练一个 SQL 模型。我们的评估数据集限制了场景,仅支持简单的关键词,如“SELECT”, “INSERT INTO”, “UPDATE”, “DELETE”, “CREATE”。
- Java + JavaScript:尽管大多数编程语言的函数调用格式相同,但每种编程语言都有其特有的类型。例如,C 有指针类型,Java 有 HashMap 类型。这个测试类别的目的是了解函数调用模型如何扩展到不仅仅是 JSON 和 Python 类型,还包括所有特定于语言的类型。
这些类别使我们能够看到不同模型在 API 调用的流行用例中的表现,并为我们提供了关于函数调用模型潜力的洞察。
评估指标 📈
我们使用两种流行的方法来评估模型生成答案的准确性:AST 检查器和执行检查器。理想情况下,应使用执行检查器,但由于并非所有结果都容易执行(如 Java 函数),我们使用 AST 作为执行检查器的补充。
- 抽象语法树(AST)检查器
- 执行检查器
AST 检查:对于可执行的函数调用答案,我们使用 AST 树进行解析。
示例:[calculate_triangle_area(base=10, height=5)]
解析:Module(body=[Expr(value=List(elts=[Call(func=Name(id='calculate_triangle_area', ctx=Load()), args=[], keywords=[keyword(arg='base', value=Constant(value=10)), keyword(arg='height', value=Constant(value=5))])], ctx=Load()))], type_ignores=[]) [calculate_triangle_area(base=10, height=5)]
我们从 AST 中提取变量,并检查每个参数是否在可能的答案中找到并精确匹配。对于每个可能的答案,应接受的答案包括:
- 布尔值:
- 我们检查布尔值的直接匹配,不允许对布尔值的字符串版本有宽容。
- 整数、浮点数:
- 答案应该是唯一的,例如 [1]
- 列表:
- 我们检查精确匹配,因此任何顺序的列表都应匹配。[1,2,3]==[2,3,1]
- 字典:
- 为简化,我们跳过检查递归 AST 字典结构。
- 字符串:
- 可能的日期 “20th June”, “2023-06-20”, “06/20/2023”, “Jun.20,2023”
- 可能的位置 [“New York City”, “NYC”]
- 可能的任何东西 [“Manchester United”, “Man United”, “Man U”, “MUFC”]
以下是一些可能的答案示例:
{"calculate_triangle_area": {"base": [10], "height": [5], "unit": ["units", "unit"]}}{"predict_house_price": {"bedrooms": [3], "bathrooms": [2], "area": [1800], "location": ["San Francisco", "San Francisco, CA"]}}
这种检查机制适用于除了 executable_*和 REST 之外的所有内容。
可执行检查:对于 executable_*和 REST,我们有相应的函数,可以为每个问题执行。因此,在模型生成答案后,我们将直接执行这些答案。有两种类型的匹配:
- 确定性的可执行输出:我们根据我们人类执行的结果检查精确匹配。
- 非确定性和现实世界相关的可执行输出:我们检查其响应类型和响应 JSON 键的一致性,看看值是否是我们期望看到的。
提示
我们提供了用于评估我们的专有和开源模型的所有提示。对于函数调用模型,我们没有提供任何系统提示,而是直接启用函数调用模式并放置函数定义。对于聊天模型,我们提供了明确的系统消息。
对于所有函数调用模型,我们直接启用函数调用模式并放置函数定义。
对于聊天模型,我们提供了明确的系统消息:
1
2
3
4
5
6
7
8
9
10
11
12
13SYSTEM_PROMPT_FOR_CHAT_MODEL = """"
你是一个编写函数的专家。你会收到一个问题和一系列可能的函数。
根据问题,你需要进行一个或多个函数/工具调用来实现目的。
如果没有一个函数可以使用,请指出。如果给定问题缺少函数所需的参数,
也请指出。你应该只在工具调用部分返回函数调用。
"""
SYSTEM_PROMPT_FOR_CHAT_MODEL = """"
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the function can be used, point it out. If the given question lacks the parameters required by the function,
also point it out. You should only return the function call in tools call sections.
"""1
2USER_MESSAGE_FOR_CHAT_MODEL = "Questions:{user_prompt}\\n这里是一系列你可以调用的JSON格式函数列表:\\n{functions}. 如果你决定返回函数调用,不得包含其他文本。"
USER_MESSAGE_FOR_CHAT_MODEL = "Questions:{user_prompt}\nHere is a list of functions in JSON format that you can invoke:\n{functions}. Should you decide to return the function call(s), NO other text MUST be included."
常见错误
通过我们的基准测试 BFCL,我们能够识别 LLMs 在生成函数调用时所犯的一些常见错误。这些错误揭示了当前模型的局限性,并为如何改进
它们提供了洞察。
GPT 的函数文档难以格式化,其类型在现实世界场景中受到限制。例如,我们需要将 float 手动转换为 number,以使函数与 OpenAI 兼容。此外,数字相比 float 在精度和类型一致性方面信息传递较少。
在 Gorilla Openfunctions-v2 中,我们通过不限制参数类型来提高函数文档的灵活性。换言之,用户可以提供 Tuple、Float,甚至 Java 中的特定类型,如 HashMap 和 LinkedList。
GPT 在需要某种隐式转换的参数场景中表现不佳。例如,当参数不是直接在用户问题中给出时。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36"Function":
{
"name": "finance.predict_future_value",
...
"parameters":
{
"type": "object",
"properties":
{
"present_value":
{
"type": "number",
"description": "The present value of the investment."
},
"annual_interest_rate":
{
"type": "number",
"description": "The annual interest rate of the investment."
},
"compounding_periods_per_year":
{
"type": "integer",
"description": "The number of times that interest is compounded per year.",
},
"time_years":
{
"type": "integer",
"description": "The investment horizon in years."
}
...
}
"required": ["present_value", "annual_interest_rate", "time_years"]
}
}Questions : Predict the future value of a $5000 investment with an annual interest rate of 5% in 3 years with monthly compounding.
1
2
3
4
5
6
7
8
9
10
11GPT-4 output:
[{
"name": "finance.predict_future_value",
"parameters":
{
"present_value": 5000,
"annual_interest_rate": 5,
"compounding_periods_per_year": 12,
"time_years": 3
}
}]1
2
3
4
5
6
7
8
9
10
11Gorilla-openfunctions-v2 output:
[{
"name": "finance.predict_future_value",
"parameters":
{
"present_value": 5000,
"annual_interest_rate": 0.05,
"compounding_periods_per_year": 12,
"time_years": 3
}
}]聊天模型倾向于生成格式错误的函数调用,其中参数可以提取但无法执行。
mistral-medium 生成的结果示例如下:
solve_quadratic_equation(a=2, b=6, c=5)。通过 gorilla-openfunctions-v2,我们能够直接输出solve_quadratic_equation(a=3, b=2, c=1),该结果在接收后即可执行。REST API 调用不一致:例如,某些情况下模型可能无法正确生成 API 调用的 URL 或参数。
结论
我们通过 Gorilla Open Functions 排行榜对 LLMs 函数调用进行了全面和系统性的评估。研究表明,在不涉及复杂规划和链式函数调用的简单函数调用方面,经过微调的开源模型可以与专有模型相媲美。此外,我们还推出了 Gorilla Open Functions v2,这是一个开源模型,可以帮助用户通过函数调用构建 AI 应用,并实现与 json 兼容的输出交互。
我们希望您喜欢这篇博客文章。欢迎您在Discord、Twitter (#GorillaLLM)和GitHub上分享您的想法。
如果您想引用 Gorilla:
1 | @misc{berkeley-function-calling-leaderboard, |
2. Gorilla OpenFunctions v2
Gorilla OpenFunctions-v2!在开源模型中技术领先(SoTA),与商业模型媲美。
Gorilla OpenFunctions 的最新版本——版本 2,带来了大语言模型(LLM)在开源社区中函数调用方面的重大进展。作为前一版本的升级替代,Gorilla OpenFunctions-v2 不仅保持了开源精神,还引入了令人兴奋的新功能。这包括支持 Python、Java、JavaScript 和 REST API 等
多种编程语言——这在开源和闭源模型中都是首次;同时具备处理多个和并行函数调用的能力,以及判断函数相关性的能力。这次更新巩固了 gorilla-openfunctions-v2 在 LLM 领域中函数调用能力的领先地位。而且,这种即插即用的更新方式使得 OpenFunctions 可以轻松集成到各种应用中,从社交媒体平台如 Instagram 到送货服务如 Doordash,还有包括 Google Calendar 和 Stripe 等实用工具。
新功能速览!! 🚀
我们在 OpenFunctions-v2 中推出的五个激动人心的新功能包括:

- 支持更多数据类型: Gorilla Open Functions v2 现在能支持多种语言,并扩展了对函数调用中参数类型的支持。例如,对于 Python,支持的类型包括
[string, number, boolean, list, tuple, dict, any];Java 和 Javascript 同样支持丰富的类型。相比之下,OpenAI 和许多其他公司仅支持 JSON 模式,即[string, number, integer, object, array, boolean]。这种对类型的原生支持意味着您现在可以更方便地使用 openfunctions-v2。 - 支持并行和多功能: 可以处理并行和多功能调用。在多功能场景中,用户可以在不确定哪个功能最合适时输入多个功能;Gorilla 模型将从中选择一个或多个(或不选择)来响应用户的请求。在并行功能中,可以通过多次调用同一功能来响应用户的提示。Gorilla 模型不仅同时支持这两种模式,还能将它们的优势结合起来。
- 功能相关性检测: 在没有提供功能或相关功能的情况下减少错误响应。Gorilla openfunctions v2 现在能自动判断提供给模型的功能是否能够解决用户的问题。识别到这一点后,LLM 会向用户展示一个错误信息,提供更多帮助。
- 增强的 RESTful API 能力: 提升了格式化 RESTful API 调用的能力。RESTful API 广泛应用于网络中,为许多流行的软件服务(如 Slack、PayPal 等)提供支持。我们的模型经过特殊训练,能够高质量地处理 RESTful API 调用。
快速链接:
- 其他功能调用模型的表现:Berkeley 功能调用排行榜
- 在线体验模型:Gorilla OpenFunctions-v2 网络演示
- 项目详情:GitHub
- 模型(7B 参数)在 HuggingFace 上的页面:gorilla-llm/gorilla-openfunctions-v2
在您的应用中集成 OpenFunctions-v2 🔨
使用 Gorilla OpenFunctions-v2 非常简单:
- 为了便于快速原型开发,我们提供了一个托管的 Gorilla Openfunctions-v2 模型供推理使用。您也可以在本地运行它,或通过 HuggingFace 的页面自行托管。以下示例展示了如何调用托管的 gorilla openfunctions v2 模型:
1 | import openai |
- 向模型提问:
波士顿和旧金山的天气怎么样? - 格式化您的功能调用:模型将根据您的请求返回功能调用。
1 | query = "波士顿和旧金山的天气怎么样?" |
- 获取您的功能调用:模型将根据您的请求返回一个 Python 功能调用。
这为开发人员和非开发人员提供了便利,使他们能够利用复杂功能而无需编写大量代码。
输入:
1 | get_gorilla_response(prompt=query, functions=[functions]) |
输出:
1 | [get_current_weather(location='Boston, MA'), get_current_weather(location='San Francisco, CA')] |
通过上面的示例,您可以利用 Gorilla OpenFunctions-v2 生成格式良好的输出,或用您自己的定义调用函数!然后,您可以在您的应用程序和聊天机器人中自由地使用这些功能!
注意:Gorilla 目前仅支持openai==0.28.1版本的托管端点。我们很快将升级以支持openai==1.xx版本,届时functions将被tool_calls替换。
Berkeley 功能调用排行榜上的表现 🔥
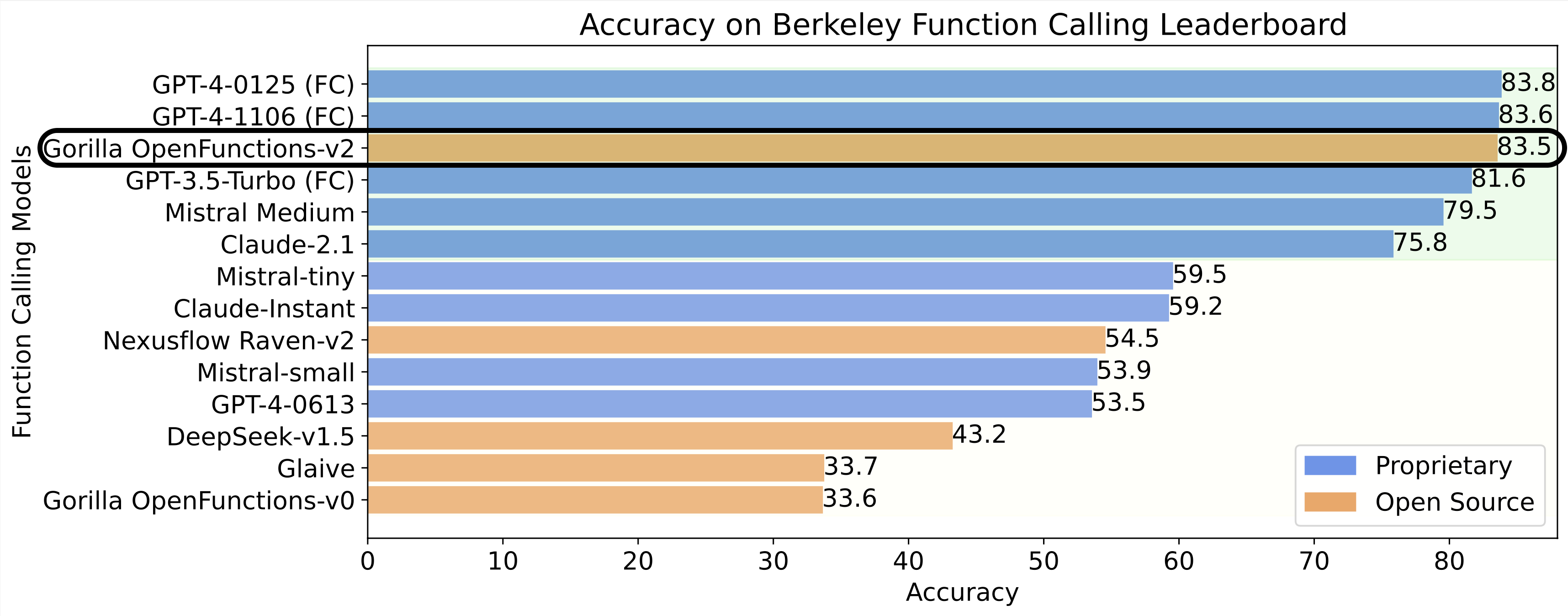
我们在 Berkeley 功能调用排行榜上进行了全面和详尽的评估,我们的模型与目前技术最先进的 GPT-4-1106 预览版以及 GPT-4 和 GPT-3.5-turbo 功能调用特性进行了对比。此外,我们还将我们的模型与其他开源模型进行了比较,展示了其优越性能。我们的评估涵盖了来自不同领域(包括旅游、金融、安排会议等)和语言(java、javascript、python、restAPI)的 2000 多个不同的查询和 API 文档对。
要深入了解我们的模型在每个类别中的表现,请参阅下面 Berkeley 功能调用排行榜中的详细表格。与目前技术最先进的 GPT-4 功能调用相比,Gorilla OpenFunctions-v2 在 Python 中的简单功能调用类别表现更优,但在涉及多个和并行功能的功能调用上表现不如 GPT-4。这一新特性对我们和整个开源社区来说仍是一个令人兴奋的研究领域。值得一提的是,我们的模型提供了非常稳定的可执行功能调用 - 这些功能调用是通过实际执行来评估的,无需任何干预。不出所料,经过训练的 Gorilla 模型在除 Python 以外的编程语言(如 Java、Javascript 和 REST API)上的功能调用上胜过了 GPT-4。对于 REST API,我们的模型提供了更稳定的输出,其中包括了所有必需的字段,包括url、params和header,使我们的模型非常适合立即采用。
左侧是 GPT-4 生成的,右侧是 openfunctions-v2 生成的。从上面的错误中可以看出,当 GPT-4 功能调用处理涉及复杂参数结构(例如字典中的字典)并带有默认值的功能时,该模型往往会遇到麻烦,尤其是在解析默认值方面。与其说是一种边缘情况,不如说上面的示例是 REST API 的一个常见范例。
OpenFunctions 数据组成与训练 🍕
Gorilla openfunctions v2 是一个基于\[deepseek-coder-7b-instruct-v1.5\]大语言模型进一步训练的 7B 参数模型。为了训练该模型,我们从三个不同来源收集了共计 65,283 个问题-功能-答案对:Python 包(19,353)、Java 存储库(16,586)、Javascript 存储库(4,245)、公共 API(6,009)以及来自各种云提供商的命令行工具(19,090)。数据组成如下图所示。
在数据收集之后,我们进行了四次数据增强,以提高我们的训练数据集的多样性。首先,我们更改了函数名称,这对于确保模型不会“记住”API 映射至关重要。其次,我们添加了随机选择的、数量不等的函数,使我们的数据集与并行函数兼容。这样我们就可以从简单的函数中生成多功能数据集。第三,我们采用扰动提示的策略来生成并行功能的场景,并将其扩展到同时包括多功能和并行功能。最后,我们还包含了一些功能在输入时不足以解决任务的数据集部分,我们将这些标记为“相关性检测”场景。与大多数 LLM 训练一样,我们对每种数据增强的程度进行了广泛的变化,以训练出一个健壮的模型。
- 函数名称变换: 我们通过使用不同的函数名称来增强原始的问题-功能-答案对,避免模型记住函数名称和问题之间的相关性(例如,“uber”API 用于交通)。
query + [{'name': 'func1', 'description': 'order takeout'}] -> ans1 => query + [{'name': 'func2', 'description': 'order takeout'}] -> [ans2] - 并行功能变换: 为了处理选择多个功能来回答用户请求的更复杂情况,我们更改了原始问题以要求多个输出。
query + [{'name': 'func1', 'description': 'order takeout'}] -> ans1 => query + [{'name': 'func1', 'description': 'order takeout'}, {'name': 'func2', 'description': 'get weather'}] -> [ans1] - 多功能变换: 在训练中包含多个功能调用的原始功能变换,使模型学习选择使用哪个功能调用。
query1 + [{'name': 'func1', 'description': 'order takeout'}] -> ans1 => query2 + [{'name': 'func1', 'description': 'order takeout'}] -> [ans1, ans2] - 并行多功能变换: 上述并行和多功能变换的结合。
query1 + [{'name': 'func1', 'description': 'order takeout'}] -> ans1 => query2 + [{'name': 'func1', 'description': 'order takeout'}, {'name': 'func2', 'description': 'get weather'}] -> [ans1, ans2] - 功能相关性检测变换: 我们还包含了一些在输入时提供的功能无法解决任务的数据集部分。我们称之为“相关性检测”。
query1 + [{'name': 'func1', 'description': 'order takeout'}] -> ans1 => query2 + [{'name': 'func1', 'description': 'order takeout'}] -> [Error, the function cannot solve the question.]
在整个数据增强之后,我们还使用 Rouge 得分进行了数据去重,这已经成为标准做法。
结论
我们很高兴发布gorilla-openfunctions-v2,这是一个在 Deepseek-Coder-7B-Instruct-v1.5 大语言模型基础上训练的 7B 参数模型。它接收用户的提示和多个 API 调用,并返回带有正确参数的功能。OpenFunctions 扩展了对 Python、Java 和 JavaScript 以及 RESTful API 中参数类型的原生支持。欲了解更多信息,请查看我们在 Berkeley 功能调用排行榜上的博客评估,以及我们 GitHub 页面上的模型。博客中的所有结果都是使用gorilla-openfunctions-v2生成的。
Licensing:
Gorilla OpenFunctions v2 is distributed under the Apache 2.0 license. This software incorporates elements from the Deepseek model. Consequently, the licensing of Gorilla OpenFunctions v2 adheres to the Apache 2.0 license, with additional terms as outlined in Appendix A of the Deepseek license.
我们希望您喜欢这篇博客文章。欢迎您在Discord、Twitter (#GorillaLLM)和GitHub上与我们分享您的想法。
如果您想引用 Gorilla:
1 |
|