使用压缩有限状态机进行本地 LLM 的快速 JSON 解码
使用压缩有限状态机进行本地 LLM 的快速 JSON 解码
作者: Liangsheng Yin, Ying Sheng, Lianmin Zheng
日期: 2024 年 2 月 5 日
本文内容基于 LMSYS Org 发布的一篇博客文章,原文链接:LMSYS Org 博客。相关的代码库可以在以下链接找到:SGLang 代码库。
让一个 LLM 始终生成符合特定模式的有效 JSON 或 YAML,对于许多应用来说是一个关键特性。在这篇博客文章中,我们介绍了一种显著加速这种约束解码的优化方法。我们的方法利用了压缩的有限状态机,并且兼容任何正则表达式,因此可以适用于任何 JSON 或 YAML 模式。与现有系统逐步解码一个标记的方式不同,我们的方法分析了正则表达式的有限状态机,压缩了单一的转换路径,并在可能的情况下一次性解码多个标记。与最先进的系统(guidance + llama.cpp,outlines + vLLM)相比,我们的方法可以将延迟减少最多 2 倍,并提高吞吐量最多 2.5 倍。这一优化还使得约束解码比普通解码更快。你可以在 SGLang 上试用它。
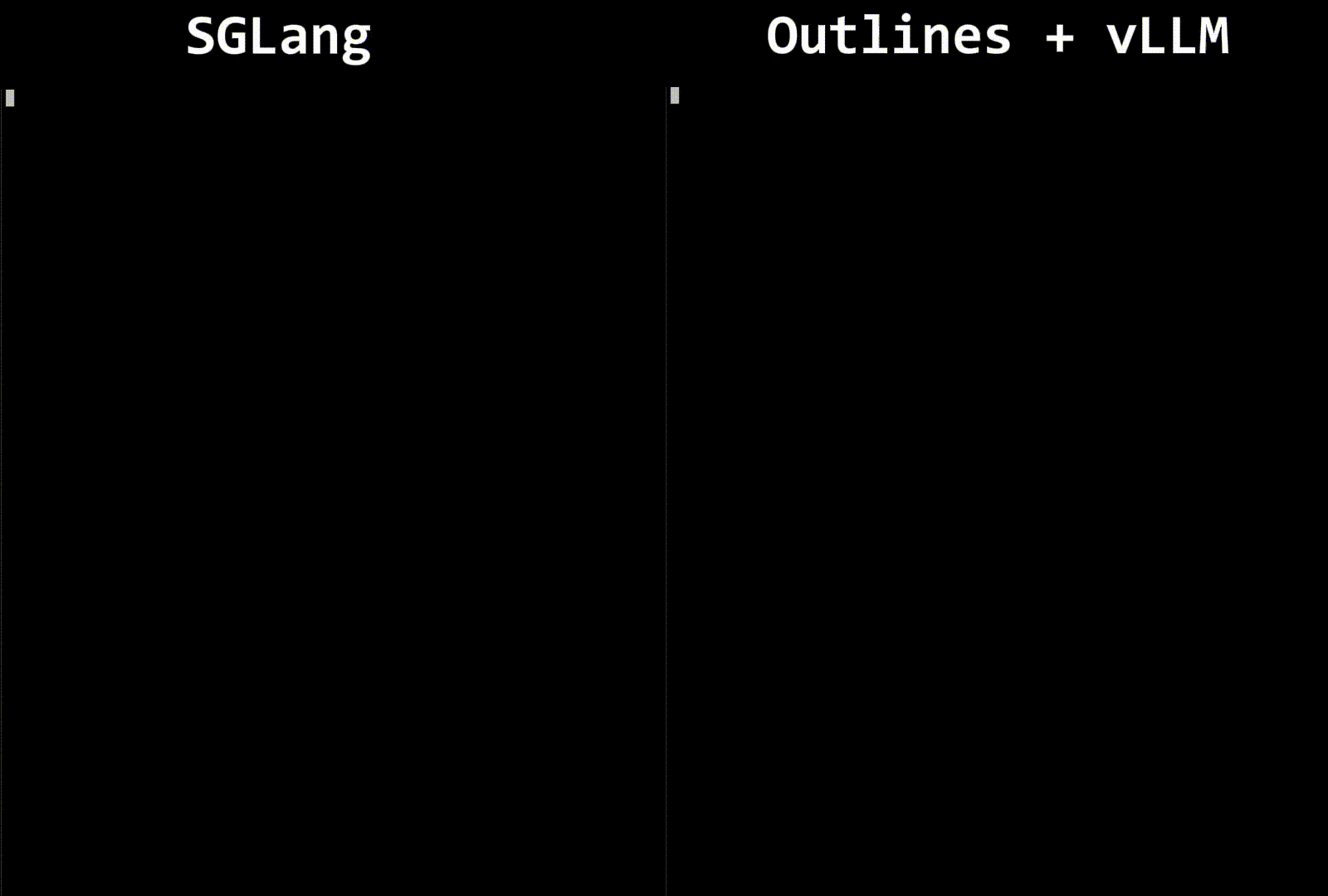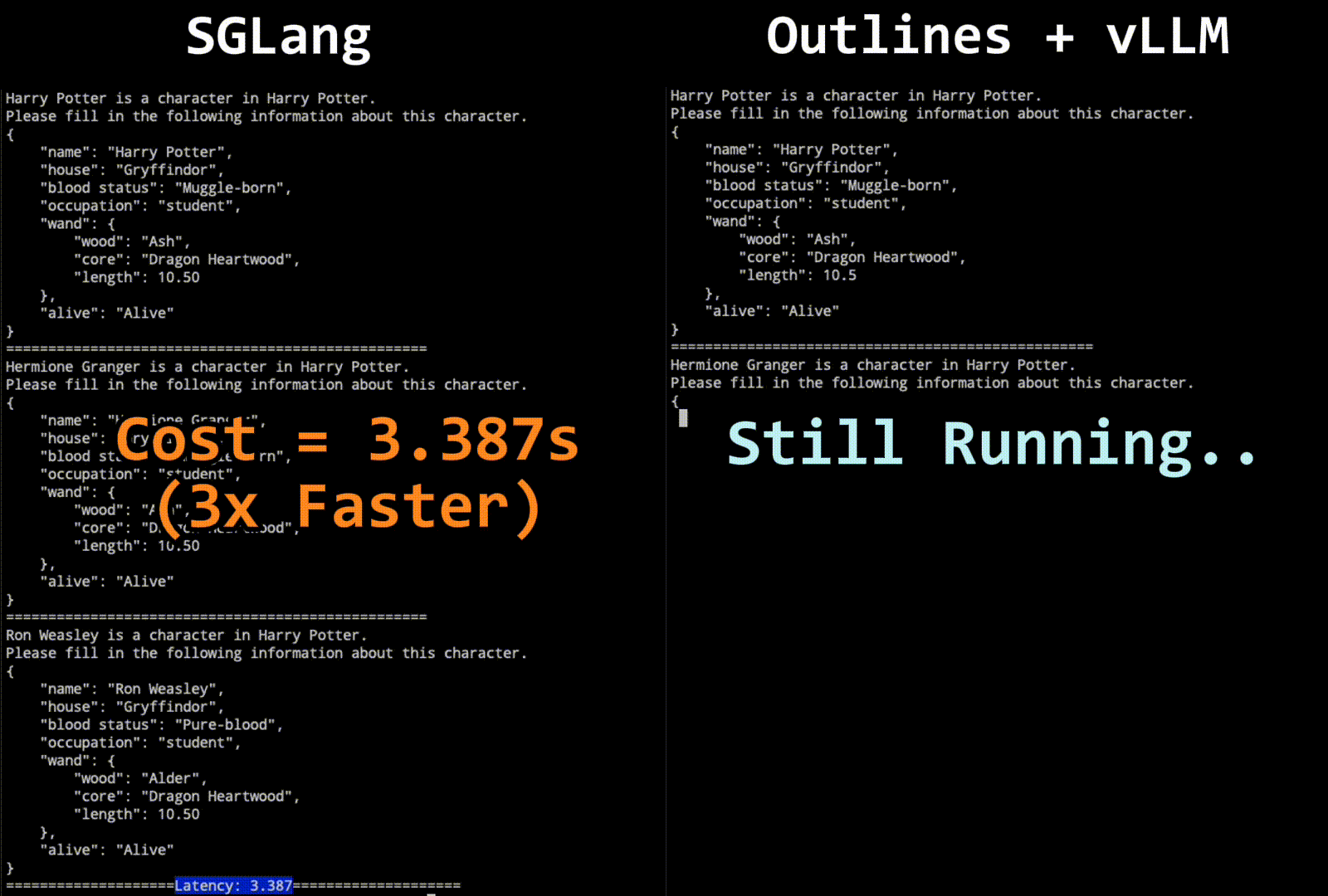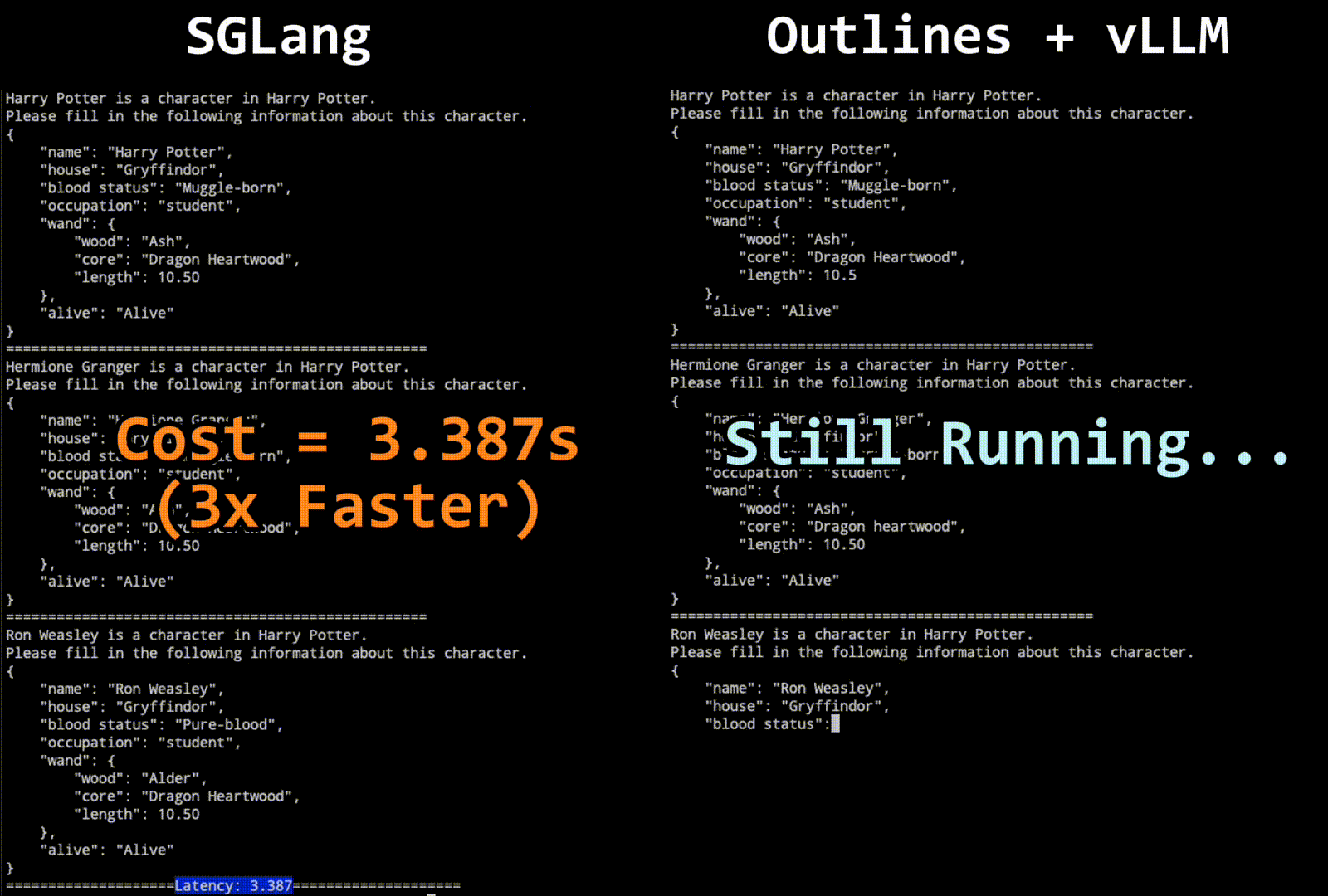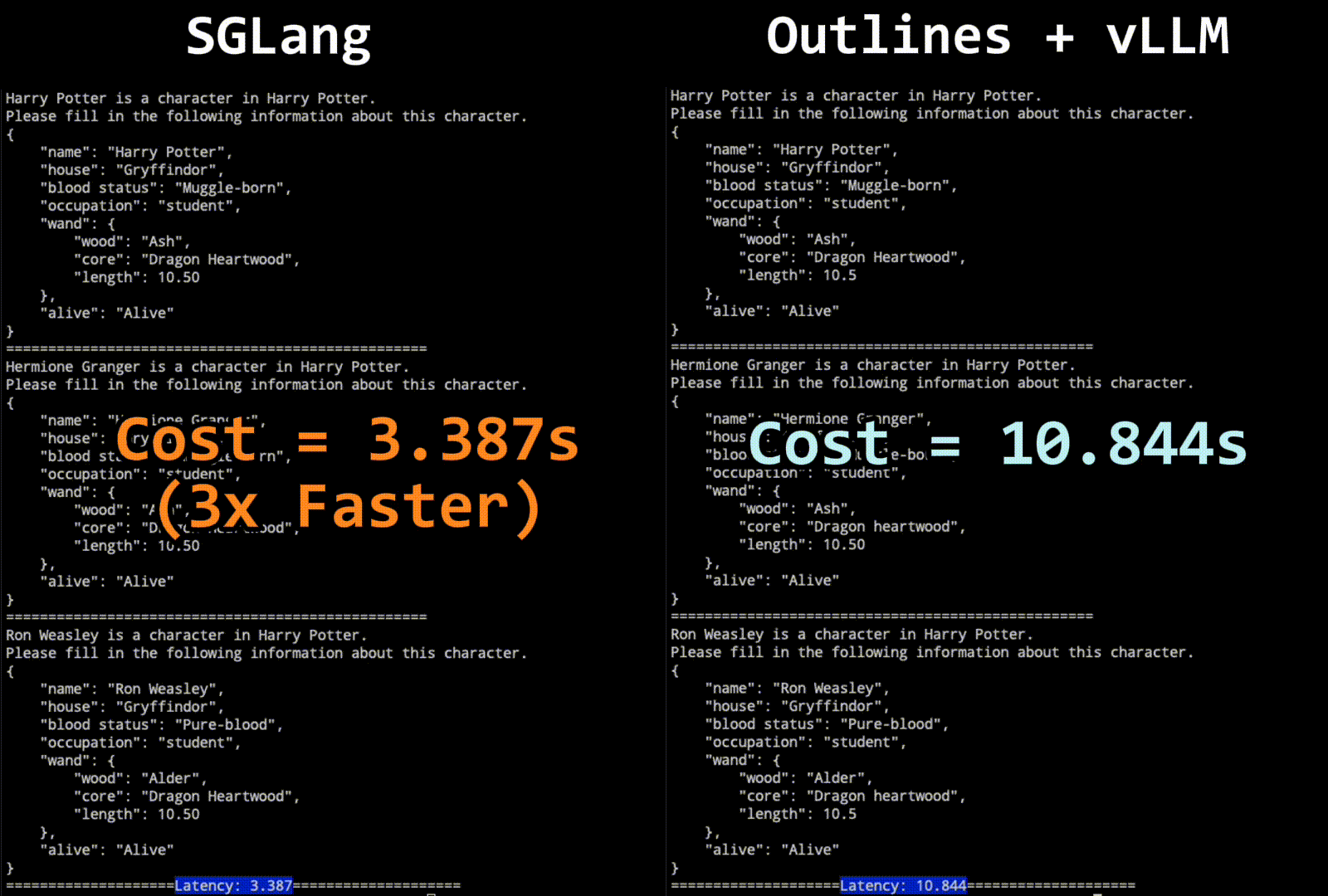
图一展示了 SGLang 和 Outlines + vLLM 在 JSON 解码任务中的性能比较。这是一个动态对比,目的是展示两者在相同任务下的速度差异。SGLang 采用了一种新的跳跃前进解码算法,通过压缩有限状态机来加速解码过程。相比之下,Outlines + vLLM 使用了传统的逐步解码方法。图中的动画演示了 SGLang 在处理多字符(或标记)解码时的优势,显著减少了解码时间。
背景
JSON 是数据交换中最重要的格式之一。要求 LLM 始终生成有效的 JSON 可以使 LLM 的输出以结构化方式轻松解析。认识到其重要性,OpenAI 引入了 JSON 模式,它约束模型始终返回有效的 JSON 对象。然而,通常需要更细粒度的控制,以确保生成的 JSON 对象符合特定的模式,例如:

图二展示了一个受限生成的例子,利用大语言模型(LLMs)来生成符合特定 JSON 模式的对象。在这个例子中,左侧的 JSON 模式定义了一个对象,其中包含了 name、age 和 house 三个属性,分别是字符串和整数类型。右侧则显示了受限生成的输出对象,模型通过约束生成技术,生成了符合这些属性的具体实例,如“Harry”的名字、15 岁的年龄以及属于“Gryffindor”的房子。这展示了 LLMs 在生成结构化数据时的能力,同时确保了生成内容符合预定的格式。
对于本地 LLM,有两种主要方法来引导模型生成符合特定模式的 JSON 对象。
方法 1:基于有限状态机
这种方法涉及将 JSON 模式转换为正则表达式。然后,我们可以基于正则表达式构建一个有限状态机(FSM)。FSM 用于引导 LLM 的生成。在 FSM 的每个状态中,我们可以计算允许的转换并识别可接受的下一个标记。这使我们能够在解码过程中跟踪当前状态,并通过对输出应用 logit 偏差来过滤掉无效的标记。你可以在 outlines 论文中了解更多关于这种方法的信息。

图三展示了如何利用有限状态机(FSM)来实现受限解码。在这个过程中,首先将 JSON 模式转换为正则表达式,然后利用 FSM 来引导 LLM 的生成。在图中,FSM 状态图展示了 age 字段的受限生成过程,其中只有合法的数字(如 0-9)会被允许。每个状态的转换由正则表达式的规则定义,确保生成的 JSON 数据始终有效。这种方法通过在生成过程中施加限制,来控制 LLM 生成特定的输出。
FSM 方法利用广义的正则表达式来定义低层次规则,可以应用于广泛的语法,例如 JSON 模式、IP 地址和电子邮件。
限制:
由于 FSM 是在标记级别构建的,因此它只能在每一步通过一个标记来转换状态。因此,它一次只能解码一个标记,导致解码速度较慢。
方法 2:基于交织
除了将整个 JSON 模式转换为正则表达式之外,另一种方法是使用基于交织的解码。在这种方法中,给定的 JSON 模式可以分解为几个部分,每个部分包含一个分块预填充部分或一个约束解码部分。这些不同的部分由推理系统交织执行。由于分块预填充可以在一个前向传递中处理多个标记,它比逐标记解码更快。
Guidance 提供了一套基于交织解码的语法规则,使用 llama.cpp 作为后端。

图四展示了 Guidance 框架中的交织语法,如何利用交织语法来进行 JSON 的解码。图中的代码片段定义了一个函数,使用 Guidance 语法生成一个包含 name、age 和 house 的 JSON 对象。交织语法通过将不同部分的解码与预填充部分交替进行,能够提高解码速度。图下方展示了这一过程的工作原理,绿色和蓝色的条形代表不同部分的处理过程,展示了交织解码在不同阶段的执行情况。
限制:
- 基于交织的方法需要自定义语法,使其不如单个正则表达式灵活和表达力强。
- 由于解码和分块预填充段之间可能存在冲突,处理标记边界时存在困难。
- 解释器与后端之间的频繁通信带来了额外的开销。
我们的方法:使用压缩有限状态机的跳跃前进解码
通过引入基于压缩有限状态机的新解码算法——跳跃前进解码,我们可以结合 FSM 和交织方法的优点。
在由 JSON 模式转换的正则表达式引导的解码过程中,当我们达到特定节点时,可以预测即将到来的字符串:
在图 3 中,解码开始时,根据正则表达式,我们可以预见到接下来的字符串是:
1 | { |
然后进入实际的解码部分。
同样,当 LLM 在为角色填写房子属性时输出了 G,我们可以自信地预测下一个字符串将是 ryffindor,从而完成整个字符串为 Gryffindor。
这正是跳跃前进解码算法加速解码的方式。在跳跃前进算法中,我们检查给定正则表达式的有限状态机,识别所有单一的转换边,并将连续的转换路径压缩为单一路径。我们可以直接预填充(扩展)这些单一路径,跳过逐标记解码,直到下一个分支点。

图五展示了跳跃前进解码与普通解码的对比。跳跃前进解码利用压缩的有限状态机,通过提前预测并预填充可能的字符串,减少了逐标记解码的次数。例如,在为 house 字段生成值时,模型在解码过程中直接跳跃并预填充了“Gryffindor”这个字符串,而无需逐字符生成。图中的流程展示了如何通过这种方法提高解码效率,同时避免了不必要的重复计算。
图五展示了压缩有限状态机的跳跃前进解码与普通解码的对比,特别是在生成 JSON 数据时的性能差异。为了更详细地理解这张图,我们需要分步骤分析图中的各个部分。
输入提示(左侧的绿色部分):提示模型生成一个符合 JSON 模式的对象。这里的 JSON 对象包括“name”、“age”和“house”三个属性,分别代表名字、年龄和学院。
跳跃前进解码过程(中间部分的蓝色和橙色方块):
- 橙色方块代表需要约束解码的部分。例如,生成“name”属性时,模型通过跳跃前进解码算法可以直接生成完整的字符串“Harry”。
- 蓝色方块代表模型在跳跃前进过程中逐字符(或逐标记)解码的部分。这种解码方式在遇到非确定性时(例如多个可能的值)才会出现。
普通解码过程(中间部分的蓝色方块):普通解码需要逐字符或逐标记地生成整个 JSON 对象。相比之下,普通解码方式在处理每一个字符或标记时都需要进行预测和选择,显著降低了解码速度。
对比结果(右侧部分):
- 跳跃前进解码生成的 JSON 对象展示在最上方,这种方法通过预测并预填充可能的字符串,大大加速了解码过程。例如,在生成“Gryffindor”这个字符串时,模型直接跳过了逐字符生成的步骤。
- 普通解码生成的 JSON 对象展示在最下方,这种方法逐字符解码,虽然能够保证生成的准确性,但效率较低,尤其是在处理长字符串或复杂结构时。
详细解读:
跳跃前进解码的工作原理:
- 在解码的过程中,模型使用压缩后的有限状态机(FSM)来预测和识别即将生成的字符串。如果模型能在当前上下文中准确预测出接下来要生成的字符串,那么它可以跳过这些字符串的逐标记解码,直接生成整个字符串(例如“Gryffindor”)。
- 这种方法利用了正则表达式的结构特点,将连续的转换路径压缩成一个单一路径,从而避免了不必要的逐标记解码步骤。
普通解码的限制:
- 普通解码方法需要逐步解码每一个字符或标记,因此在处理复杂的 JSON 对象时效率较低。每一步都需要模型重新计算可能的输出,并从中选择最优解,这会大幅增加解码时间。
性能差异:
- 由于跳跃前进解码减少了逐字符解码的次数,并且利用了 FSM 的压缩特性,它在时间和计算资源上的开销都显著低于普通解码。尤其在需要生成大量数据或处理复杂结构时,跳跃前进解码的优势更加明显。
SGLang 的 RadixAttention 机制极大地简化了跳跃前进解码算法的实现。当执行跳跃前进时,我们可以简单地终止当前请求并排入新请求。SGLang 运行时的 RadixAttention 和高效的扩展原语将自动重用前一组标记的 KV 缓存,从而避免冗余计算。
标记边界处理
在实现约束解码时,由于字符与标记之间复杂的可能映射关系,处理标记边界总是很棘手。
在 LLM 解码过程中,它可能更倾向(意味着概率更高)于将多个字符组合成一个标记。例如,在 JSON 解码的上下文中解码”Hello”时,LLM 可能会输出如下标记:
“ He llo “,
而不是解码最后的” ,它总是倾向于将其与后续字符组合成更常见的标记”, 这种效果可能导致一些奇怪的行为。例如,在上述情况下,如果正则表达式设置为”[\w\d\s]*“(不包含最后的”, ),这可能会导致无限解码,因为 LLM 想要停止于”,但该标记是不允许的。
此外,在跳跃前进解码过程中,我们发现对跳跃前进部分使用不同的标记策略可能会导致后续标记的 logit 分布不同。简单地将标记化的跳跃前进部分附加到当前的标记序列中可能会产生意外的结果。
为了解决这些问题,我们提出了以下解决方案:
- 我们在跳跃前进阶段实施了重新标记化机制。这包括附加字符串而不是标记,然后重新标记整个文本。这种方法有效地解决了大多数标记化问题,并且仅导致计算开销增加约 4%。
- 建议使用综合正则表达式引导整个解码过程,而不是使用多个连接的正则表达式。这种方法确保 FSM 和 LLM 都了解整个解码过程,从而尽量减少与边界相关的问题。
你还可以在这篇博客文章中阅读一些额外的讨论。
基准测试结果
我们在两个任务上对我们的跳跃前进解码进行了基准测试:
- 使用简短的提示生成 JSON 格式的角色数据。
- 从长文档中提取城市信息并以 JSON 格式输出。
我们在 NVIDIA A10 GPU(24GB)上测试了 llama-7B,使用了 vllm v0.2.7,guidance v0.1.0,outlines v0.2.5 和 llama.cpp v0.2.38(Python 绑定)。下图显示了这些方法的吞吐量(使用每个系统支持的最大批次大小)和延迟(批次大小为 1):

结果表明,使用我们的解码算法的 SGLang 显著优于所有其他系统。它可以将延迟减少最多 2 倍,并将吞吐量提高最多 2.5 倍。在角色生成任务中,即使不使用跳跃前进的 SGLang 也比 Outlines+vLLM 实现了更高的吞吐量;我们怀疑这是由于 Outlines 中的某些开销所致。
用例
我们已经与 Boson.ai 测试了这个功能两周,他们正在将这个功能引入他们的生产用例中,因为它保证了更高的解码吞吐量和可靠的响应。
此外,另一位用户使用此功能通过视觉语言模型 LLaVA 从图像中提取结构化信息。
