FAISS向量查询简介
Faiss
Install
- 支持 CUDA 的 Linux :
conda install -c pytorch faiss-gpu - 其他:
conda install -c pytorch faiss-cpu
IndexFlatL2
IndexFlatL2
测量查询向量与加载到索引中的向量之间所有给定点之间的 L2(或欧几里得)距离。它很简单,非常准确,但也不会太快。
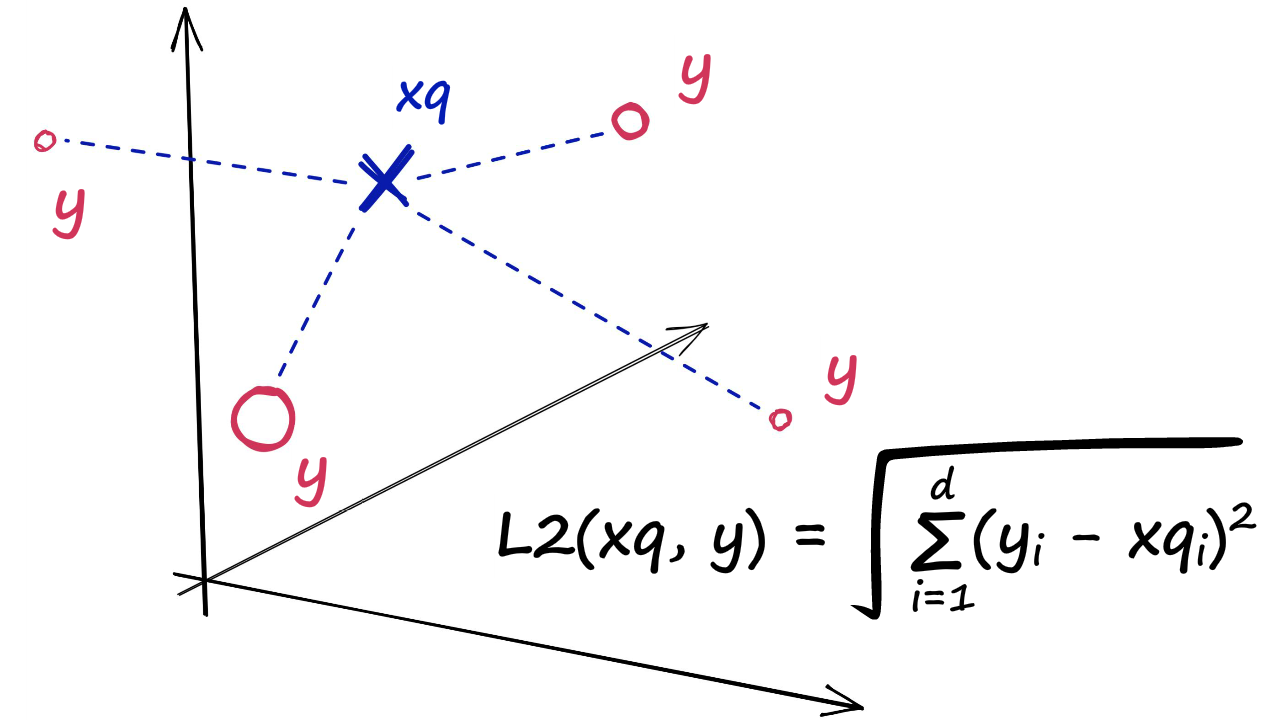
给定一组维度为$d$的向量${ x_1,…, x_n }$,Faiss在Ram中构架一个数据结构——index ,构造完结构后,当给定一个新的维度为$d$向量$x$时,可以高效的执行以下操作:
$$
i = \mathrm{argmin}_i || x - x_i ||
$$
其中$||.||$表示欧氏(Euclidean distance)距离(L2)
用 Faiss 术语来说,数据结构是一个*index,index 是一个具有add方法的对象。*add可以用于添加 x_i向量。请注意,假定 x_i是固定的。
在 Python 中,我们会IndexFlatL2用我们的向量维度(768——我们句子嵌入的输出大小)初始化我们的索引,如下所示:
1 | import faiss |
通常,我们使用的索引需要我们在加载数据之前对其进行训练。
在 Faiss 中,**Index** 是建立在向量数据集上的索引结构,用于支持在向量数据集中进行快速相似性搜索。**is_trained** 是 Index 类的一个方法,用于检查索引结构是否已经被训练(即初始化)。
如果 index.is_trained 返回 True,则表示索引已经被训练并已经准备好接受查询。换句话说,这意味着索引结构已经被初始化,可以对其进行读取、添加或删除向量,并使用它执行相似性搜索操作。如果 index.is_trained 返回 False,则表示索引尚未被训练,并且需要使用向量数据集进行初始化才能进行查询操作。
准备就绪后,我们加载我们的嵌入和查询,如下所示:
1 | index.add(sentence_embeddings) |
add() 是 Index 类的一个方法,用于将向量数据添加到索引中。**sentence_embeddings** 是一个包含向量的数组,每个向量对应一个句子的嵌入。
index.ntotal 是 Index 类的另一个属性,用于返回当前索引中包含的向量数量。在使用 add() 方法将 sentence_embeddings 中的向量添加到索引中后,可以通过调用 index.ntotal 方法来获取索引中已包含的向量数量。这可以用于检查索引是否已正确地添加所有向量。
例如,如果 sentence_embeddings 中有100个句子的嵌入向量,并且这些向量已通过 add() 方法添加到索引中,则 index.ntotal 方法将返回100,表示索引中现在包含100个向量。
1 | k = 4 |
在这段代码中,**k** 是一个整数变量,表示在进行相似性搜索时要返回的最近邻向量的数量。在 Faiss 中,相似性搜索可以使用 Index 类的 search() 方法来完成,该方法将查询向量作为输入,并返回与其最相似的 k 个向量。
另外,**model.encode(["Someone sprints with a football"])** 是用来计算输入句子的嵌入向量的方法调用。这个方法使用预先训练好的模型将输入的句子转换为一个向量表示,该向量表示包含输入句子的语义信息。
因此,将上述代码中的两个部分结合起来,可以得到一个查询向量 **xq**,它表示句子 “Someone sprints with a football” 的嵌入向量。然后,可以使用 Index 类的 search() 方法来查找与 xq 最相似的 k 个向量,并返回这些向量的索引列表和相似度得分列表。
1 | %%time |
在这段代码中,**%%time** 是 Jupyter Notebook 中的一种魔术命令,用于测量代码单元格的运行时间。**D** 和 I 是在使用 Index 类的 search() 方法进行相似性搜索时返回的两个结果。
具体来说,**D** 是一个包含相似度得分的数组,表示查询向量 xq 与检索到的 k 个最相似向量之间的相似度。**I** 是一个包含相应向量的索引的数组,表示与查询向量 xq 最相似的 k 个向量在索引数据集中的索引位置。
因此,将上述代码中的两个部分结合起来,可以使用 **Index**类的 **search()**方法在索引中查找与查询向量 **xq**最相似的 **k**个向量,并返回这些向量的索引列表和相似度得分列表。然后,使用 **print(I)**来输出检索到的最相似的向量的索引列表。由于 **%time**魔术命令被使用,该代码单元格还会打印出该代码单元格的执行时间。
Partitioning The Index
Faiss 允许我们添加多个步骤,这些步骤可以使用许多不同的方法优化我们的搜索。
一种流行的方法是将索引划分为 Voronoi 单元
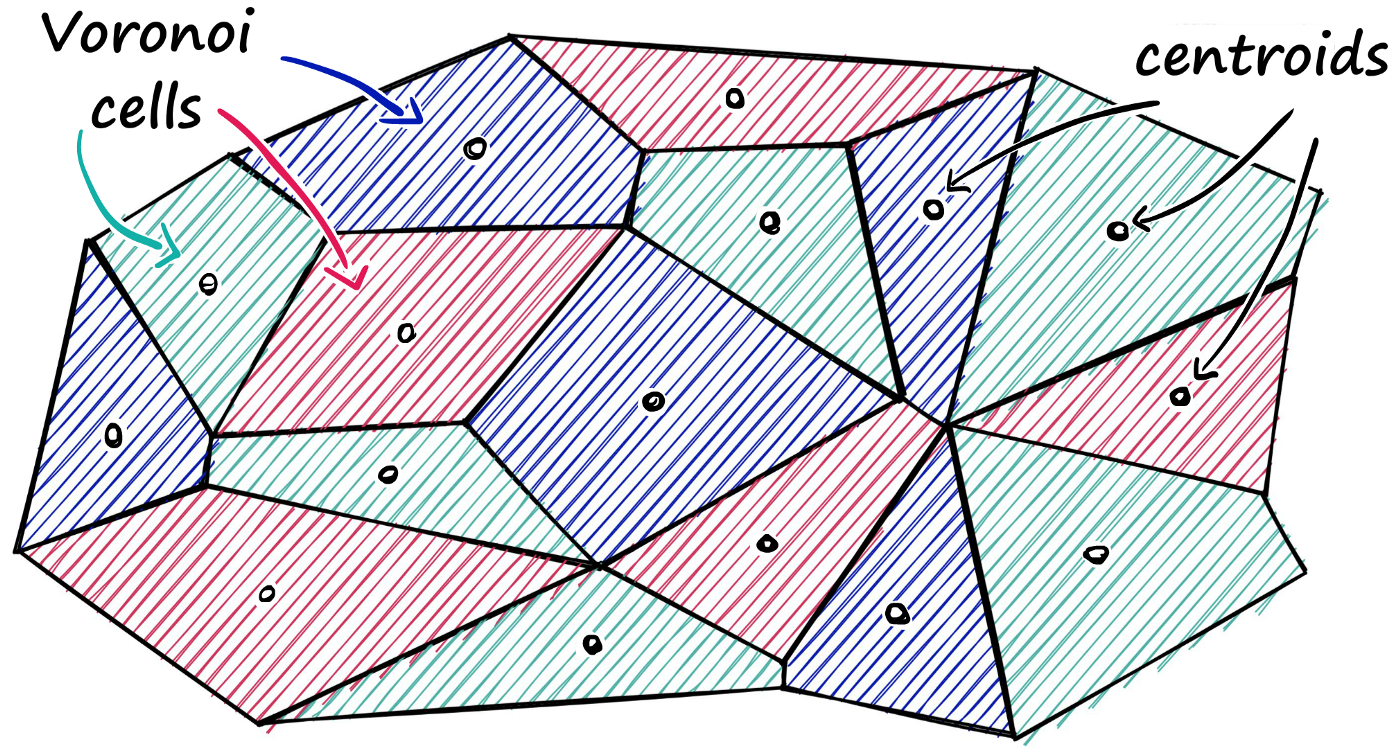
我们可以将我们的向量想象成每个向量都包含在一个 Voronoi 单元中——当我们引入一个新的查询向量时,我们首先测量它的质心之间的距离,然后将我们的搜索范围限制在该质心的单元内。
使用这种方法,我们将获取一个查询向量xq,识别它所属的单元格,然后使用我们的IndexFlatL2(或另一个度量)在查询向量和属于该特定单元格的所有其他向量之间进行搜索。
因此,我们正在缩小搜索范围,生成一个近似答案,而不是精确答案(通过详尽搜索得出)。
为了实现这一点,我们首先初始化我们的索引IndexFlatL2——但这次,我们使用 L2 索引作为量化器步骤——我们将其输入分区索引IndexIVFFlat。
1 | nlist = 50 # how many cells |
在这段代码中,nlist 是一个整数变量,用于指定 IVF(inverted file)索引中存储的聚类中心数,即将数据集划分为多少个子集。quantizer 是一个 Faiss 索引对象,用于将向量分配到 IVF 索引的子集中。在这里,我们使用了 Faiss 提供的 IndexFlatL2 类型作为 quantizer,它使用欧几里得距离度量来计算向量之间的相似度,并将向量存储在一个平面的索引结构中。
另外,d 是一个整数变量,表示嵌入向量的维度大小。这个值是根据预训练的模型和嵌入向量的特征维度确定的。
最后,index 是一个 Faiss 索引对象,用于支持在向量数据集中进行快速相似性搜索。在这里,我们使用了 IndexIVFFlat 类型作为 index,它使用了一种称为倒排文件(inverted file)的数据结构来组织向量数据集,并使用 quantizer 来将向量分配到不同的子集中。这种索引结构可以加速相似性搜索,并且在存储大规模向量数据集时非常有效。
1 | index.is_trained |
1 | index.train(sentence_embeddings) |
1 | index.add(sentence_embeddings) |
现在我们的索引已经过训练,我们可以像以前一样添加数据。
让我们使用相同的索引句子嵌入和相同的查询向量再次搜索xq
1 | %%time |
Quantization
到目前为止,我们所有的索引都将我们的向量存储为完整的(例如Flat)向量。现在,在非常大的数据集中,这很快就会成为一个问题。
Faiss 具有使用乘积量化 (PQ)压缩向量的能力。我们可以将其视为一个额外的近似步骤,其结果与我们使用IVF的结果相似。在 IVF 允许我们通过缩小搜索范围进行近似的情况下,PQ 改为近似计算距离/相似性。
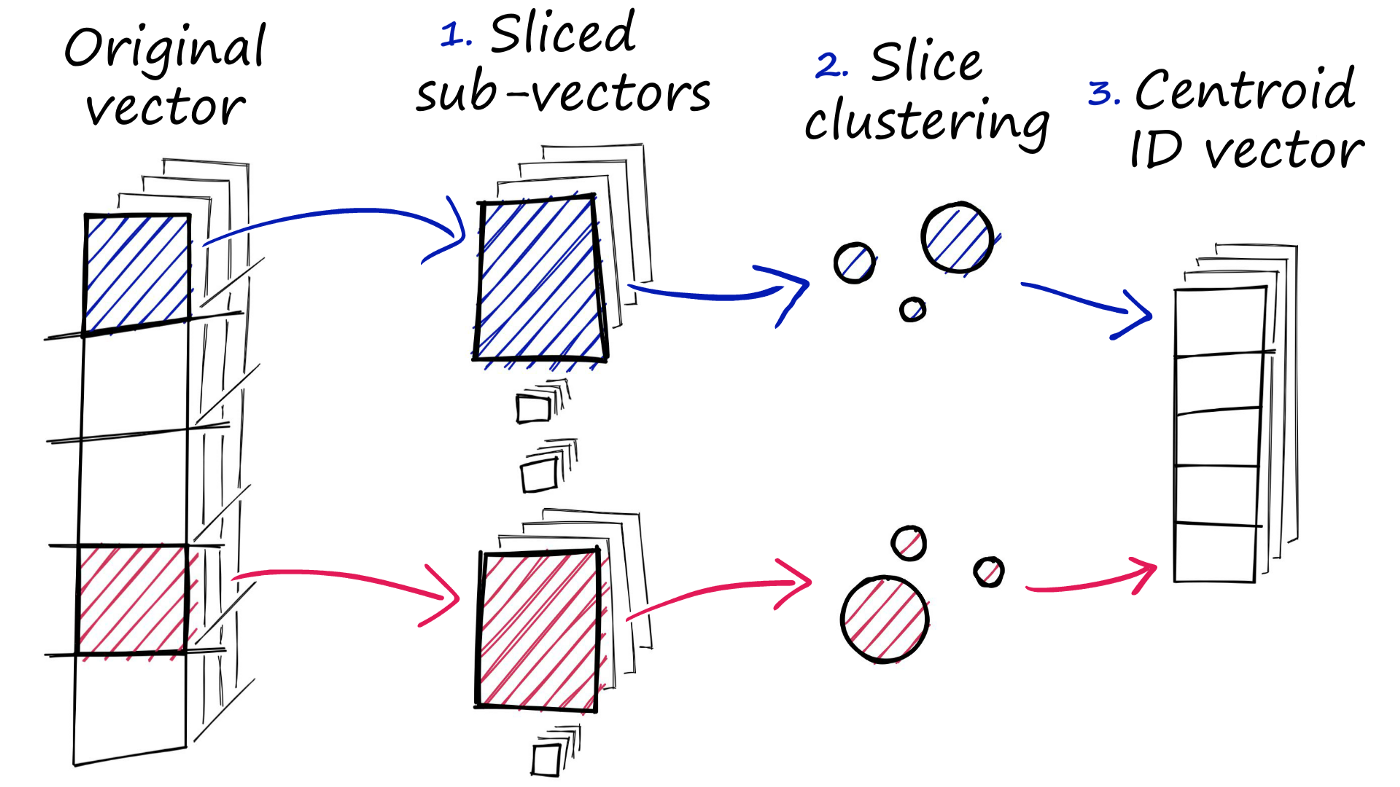
- 我们将原始向量拆分为几个子向量。
- 对于每组子向量,我们执行聚类操作——为每个子向量集创建多个质心。
- 在子向量中,我们用它最近的特定集合质心的 ID 替换每个子向量
我们使用 IndexIVFPQ 训练索引——在添加嵌入之前我们还需要索引
1 | m = 8 # number of centroid IDs in final compressed vectors |
**m**是一个整数变量,表示对每个向量进行矢量量化后,要保留的聚类中心的数量。聚类中心是通过使用 K-means 聚类算法从向量数据集中选择的一组代表性向量,可以用来近似表示原始向量。
**bits**是一个整数变量,用于指定矢量量化后每个聚类中心的位数。较高的 bits
值可以提高矢量量化的准确性,但也会增加存储和计算成本。
另外,**quantizer** 是一个 Faiss 索引对象,用于将向量分配到 IVF 索引的子集中。在这里,我们使用了 Faiss 提供的 IndexFlatL2 类型作为 **quantizer**,它使用欧几里得距离度量来计算向量之间的相似度,并将向量存储在一个平面的索引结构中。
最后,**index** 是一个 Faiss 索引对象,用于支持在向量数据集中进行快速相似性搜索。在这里,我们使用了 IndexIVFPQ 类型作为 **index**,它使用了一种称为倒排文件(inverted file)的数据结构来组织向量数据集,并使用矢量量化和乘积量化(product quantization)技术来压缩向量。这种索引结构可以加速相似性搜索,并且在存储大规模向量数据集时非常有效。
Nearest Neighbour Indexes for Similarity Search
Flat
应该首先查看的索引是最简单的——平面索引。
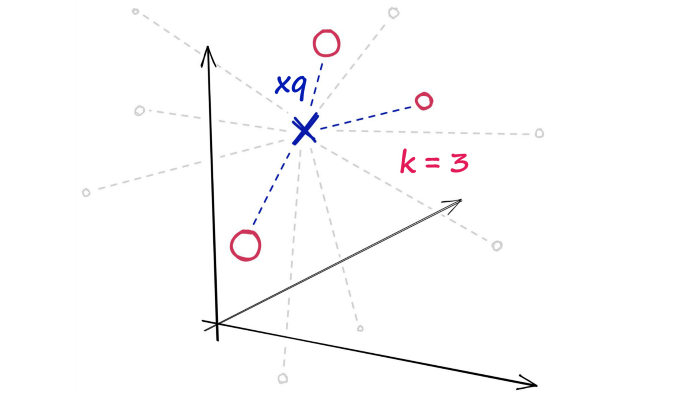
Flat索引是“平面”的,我们不修改输入向量。由于向量没有近似值或聚类——这些索引产生最准确的结果。我们拥有完美的搜索质量,但这是以大量搜索时间为代价的。使用Flat索引,我们引入查询向量xq并将其与索引中的所有其他全尺寸向量进行比较——计算到每个向量的距离。
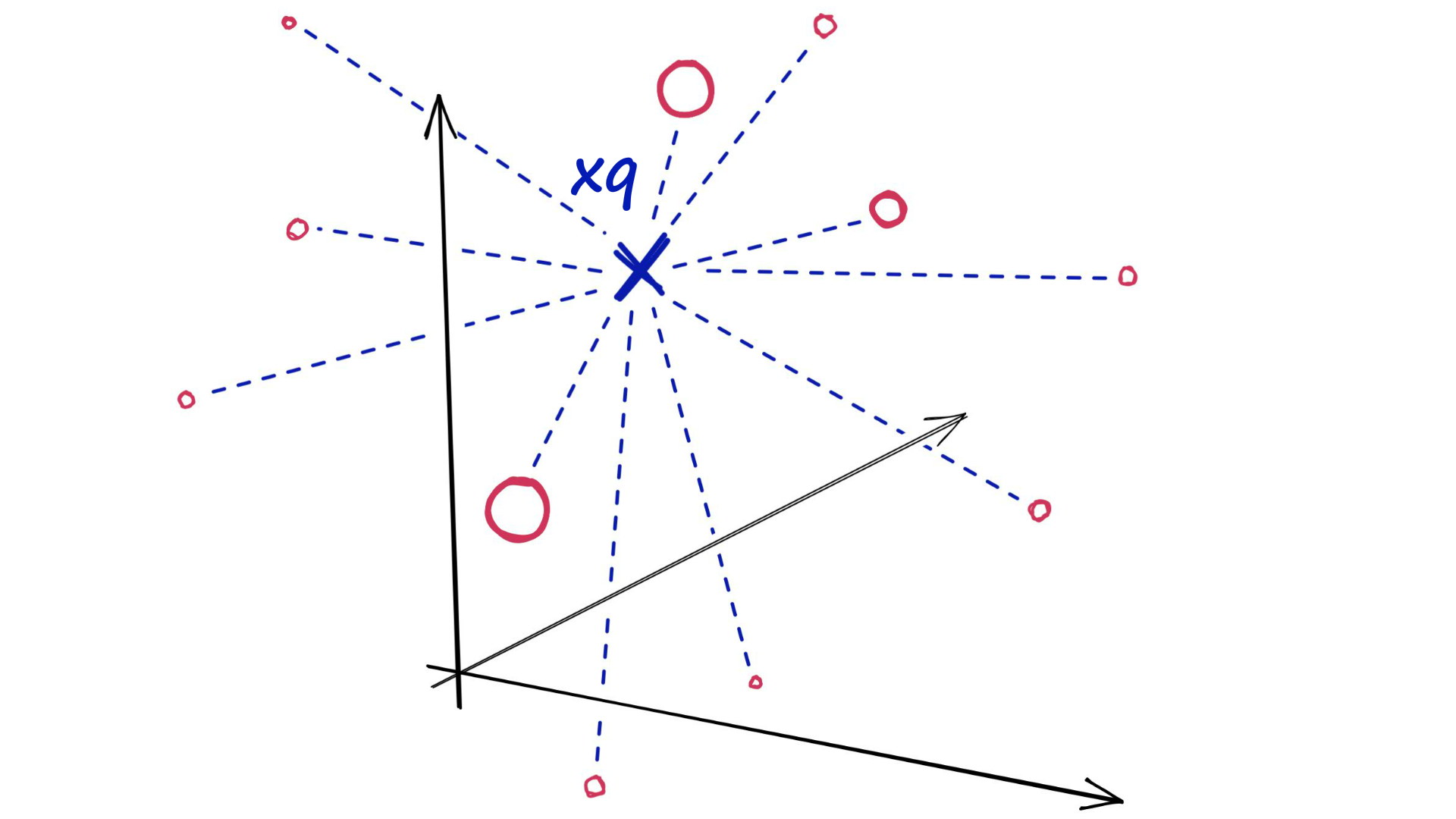
使用Flat索引,我们将搜索查询xq与索引中的每个其他向量进行比较。
在计算完所有这些距离后,我们将返回最近的 k 个作为我们最近的匹配项。
k 最近邻 (kNN) 搜索。
那么什么时候应该使用扁平索引呢?当搜索质量无疑是一个高优先级时——搜索速度就不那么重要了。此外对于较小的数据集,搜索速度可能是一个无关紧要的因素——尤其是在使用更强大的硬件时。
简而言之,在以下情况下使用平面索引:
- 搜索质量是一个非常高的优先级。
- 搜索时间无关紧要或使用小索引(<10K)时。
怎样才能使我们的搜索更快呢?有两种主要方法:
- 减少向量大小——通过降维或减少表示向量值的位数。
- 缩小搜索范围——我们可以根据某些属性、相似性或距离将向量聚类或组织成树结构——并将我们的搜索限制在最近的集群或过滤最相似的分支。
使用这两种方法中的任何一种都意味着我们不再执行详尽的最近邻搜索,而是执行近似最近邻 (ANN) 搜索——因为我们不再搜索整个全数据集。
Locality Sensitive Hashing
局部敏感哈希(Locality-Sensitive Hashing,LSH)是一种用于在高维空间中快速近似搜索相似对象的技术。在很多现实世界的问题中,我们需要对高维向量(比如图像、音频、文本等)进行相似性搜索,但是传统的线性搜索方法在高维空间中效率非常低下,因为随着维度的增加,搜索的复杂度呈指数级增长。
LSH是一种通过哈希函数将相似的向量映射到同一个“桶”中的技术,因此可以大大减少需要比较的向量数量,从而提高搜索效率。具体来说,LSH将每个向量映射到多个哈希表中,每个哈希表由多个哈希函数组成。对于一个查询向量,LSH会将其映射到每个哈希表中,然后只对同一个桶中的向量进行相似性比较。
LSH可以根据不同的相似性度量来设计不同的哈希函数,例如欧几里得距离、余弦相似度等。不同的哈希函数可以在不同的空间中捕捉到向量的不同特征,从而适应不同的应用场景。
局部敏感哈希 (LSH) 的工作原理是将向量分组到桶中,方法是通过哈希函数处理每个向量,该哈希函数最大化哈希冲突,而不是像通常使用哈希函数那样最小化。
这意味着什么?假设我们有一个 Python 字典。当我们在字典中创建一个新的键值对时,我们使用散列函数对键进行散列。这个键的哈希值决定了我们存储其各自值的“桶”:
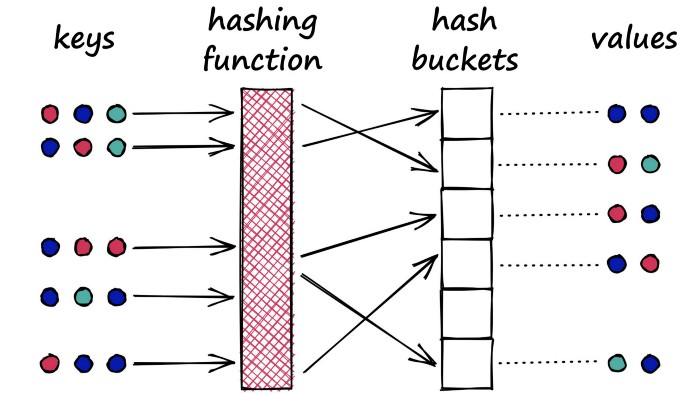
Python 字典是哈希表的一个示例,它使用典型的哈希函数来最小化哈希冲突,即两个不同对象(键)产生相同哈希的哈希冲突。
在我们的字典中,我们希望避免这些冲突,因为这意味着我们会将多个对象映射到一个键——但对于 LSH,我们希望最大化散列冲突。
为什么我们要最大化碰撞?那么,对于搜索,我们使用 LSH 将相似的对象分组在一起。当我们引入一个新的查询对象(或向量)时,我们的 LSH 算法可以用来找到最接近的匹配组:
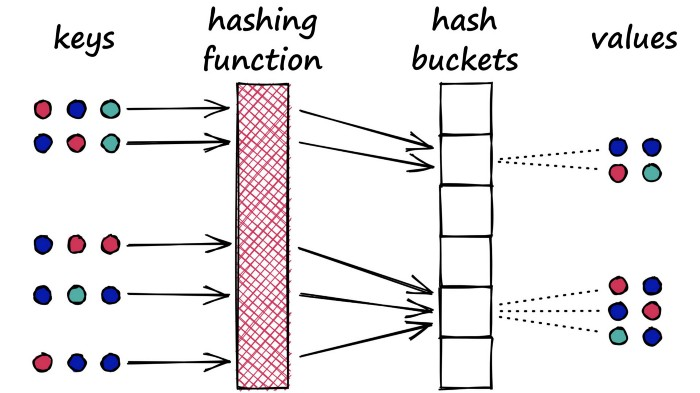
我们的 LSH 散列函数试图最大化散列冲突,产生向量分组。
1 | nbits = d*4 # resolution of bucketed vectors |
这段代码使用了Faiss库中的LSH索引,其中d是向量的维度,nbits是哈希值的位数,nbits的取值通常是d的某个倍数,这里设置为d*4。
在初始化索引后,代码通过**add方法将所有的sentence embeddings添加到LSH索引中。接下来,代码通过search**方法在LSH索引中搜索与查询向量xq最相似的k个向量,返回的D是相似度分数,I是对应的向量索引。
值得注意的是,Faiss的LSH索引使用哈希函数将向量映射到桶(bucket)中,每个桶中包含一组相似的向量。因此,LSH索引适用于高维稀疏向量的相似性搜索,其中相似向量集中在少数的桶中,从而减少搜索的时间复杂度。但是,LSH索引的准确性可能会受到哈希冲突的影响,需要根据具体的应用需求进行调整。
nbits是指散列向量的“分辨率”。更高的nbits值意味着更高的准确性,但会占用更多的内存和更慢的搜索速度。一般情况下,nbits越大,哈希计算复杂度也越高。这是因为nbits的增加会使得哈希值空间变得更大,从而增加计算哈希值所需要的运算量和存储空间。
Hierarchical Navigable Small World Graphs
Hierarchical Navigable Small World(HNSW)是一种用于高维向量索引的算法,旨在提供快速和准确的相似度搜索。它是在Small World网络和Navigable Small World算法的基础上进一步发展而来的。
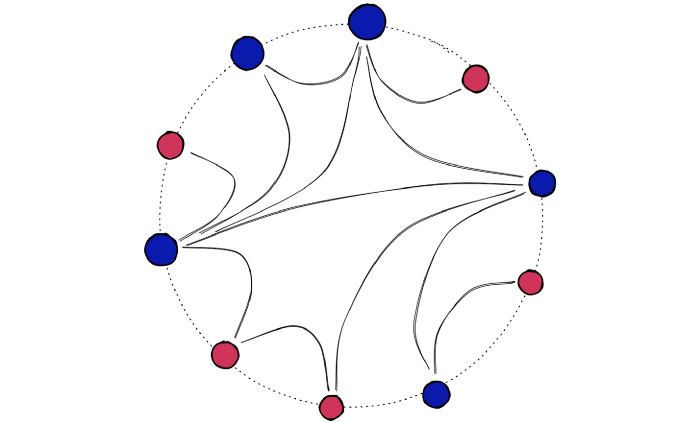
HNSW算法将高维空间中的向量表示为节点,并构建一棵树结构来组织这些节点。树中的每个节点都表示一个向量,并保存该向量在索引中的位置以及与其他节点的相似度信息。HNSW使用近似的相似度计算方法来连接节点,这使得树的结构可以在高维空间中快速导航。
在构建HNSW索引时,首先构建一个稠密的初始图。然后,将节点逐步添加到图中,并使用近似的相似度计算方法来连接节点。这些连接在不同层次的树结构中被建立,从而形成了一组层次结构。HNSW使用这种层次结构来加速相似度搜索,从而提高了搜索效率。
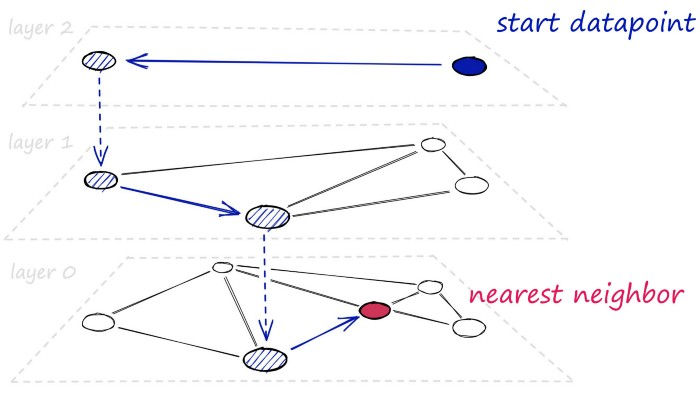
相比于传统的树型结构和线性扫描方法,HNSW具有更高的搜索效率和更好的可扩展性。它在大规模高维向量的相似度搜索任务中表现出色,并被广泛应用于图像、文本、语音等领域的数据挖掘和机器学习任务中。
1 | # set HNSW index parameters |
这段代码使用了HNSW算法来构建高维向量的索引,并进行相似度搜索。
其中
M是每个节点连接的近邻数目,即每个节点在构建索引时最多连接M个最近邻节点。ef_search是在搜索时遍历的层数,即搜索的深度,ef_construction是在构建索引时使用的遍历层数。
这些参数可以调整来平衡搜索时间和索引构建时间之间的权衡。
M和efSearch对搜索时间有更大的影响;efConstruction主要是增加了索引构建时间(意味着更慢index.add)
接下来,使用faiss.IndexHNSWFlat初始化HNSW索引。然后,将efConstruction和efSearch参数设置为预定义的值。最后,使用index.add方法将向量数据添加到索引中。
最后一行代码使用index.search方法进行搜索。它会返回查询向量wb在索引中的k个最近邻向量的距离和索引位置。